Big Data Management
Big data platforms and data lakes accumulate vast amounts of data. This data is usually not as well-structured and understood as the data produced by traditional data integration processes and stored in data warehouses. As a result, providing, finding, and protecting this data requires advanced data management technology.
The consequences of ungoverned big data are dire.
Data swamps
Data lakes turn into data swamps, leading to wasted storage costs and underutilization of data.
Lack of data security
Data protection and privacy are even more complicated than in traditional data environments.
Lack of understanding
Data people lack data discovery tools and waste time finding data, understanding it, and preparing it.
Poor data quality
Data people cannot trust the data and data engineers are constantly under pressure to fix data pipelines.
Complicated data source onboarding
Duplicate and complicated configuration of data quality transformations for each new data source.
Successful big data management includes data discovery, standardization and cleansing, self-service access to data, data preparation, and support for stream processing.
Discover your whole data lake and protect sensitive information
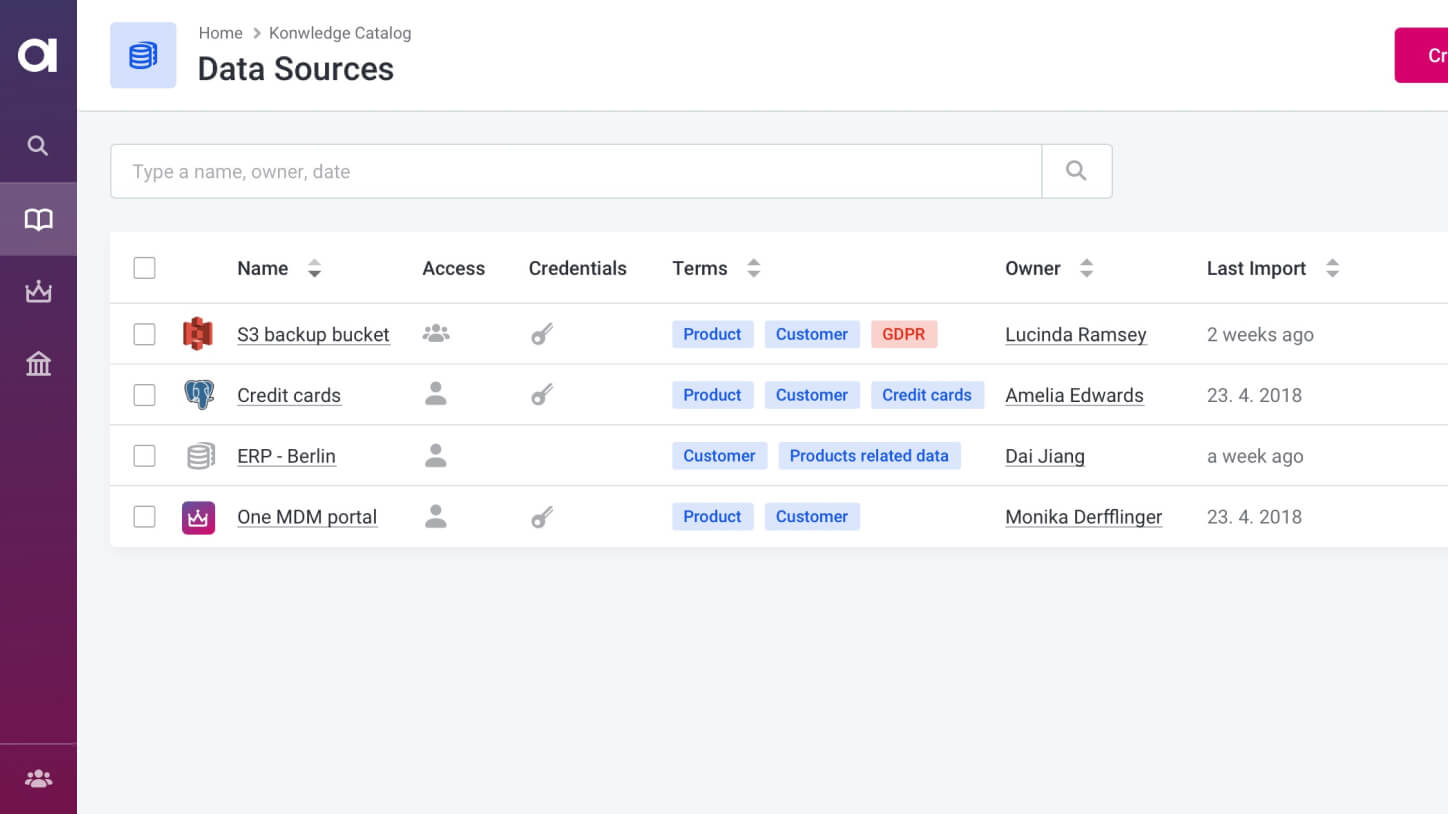
Connect all of your big data sources
A single place for connecting and managing your big data and non-big data sources alike.
Classify data
Always have an up-to-date view of the data in your data lake or cloud data warehouse.
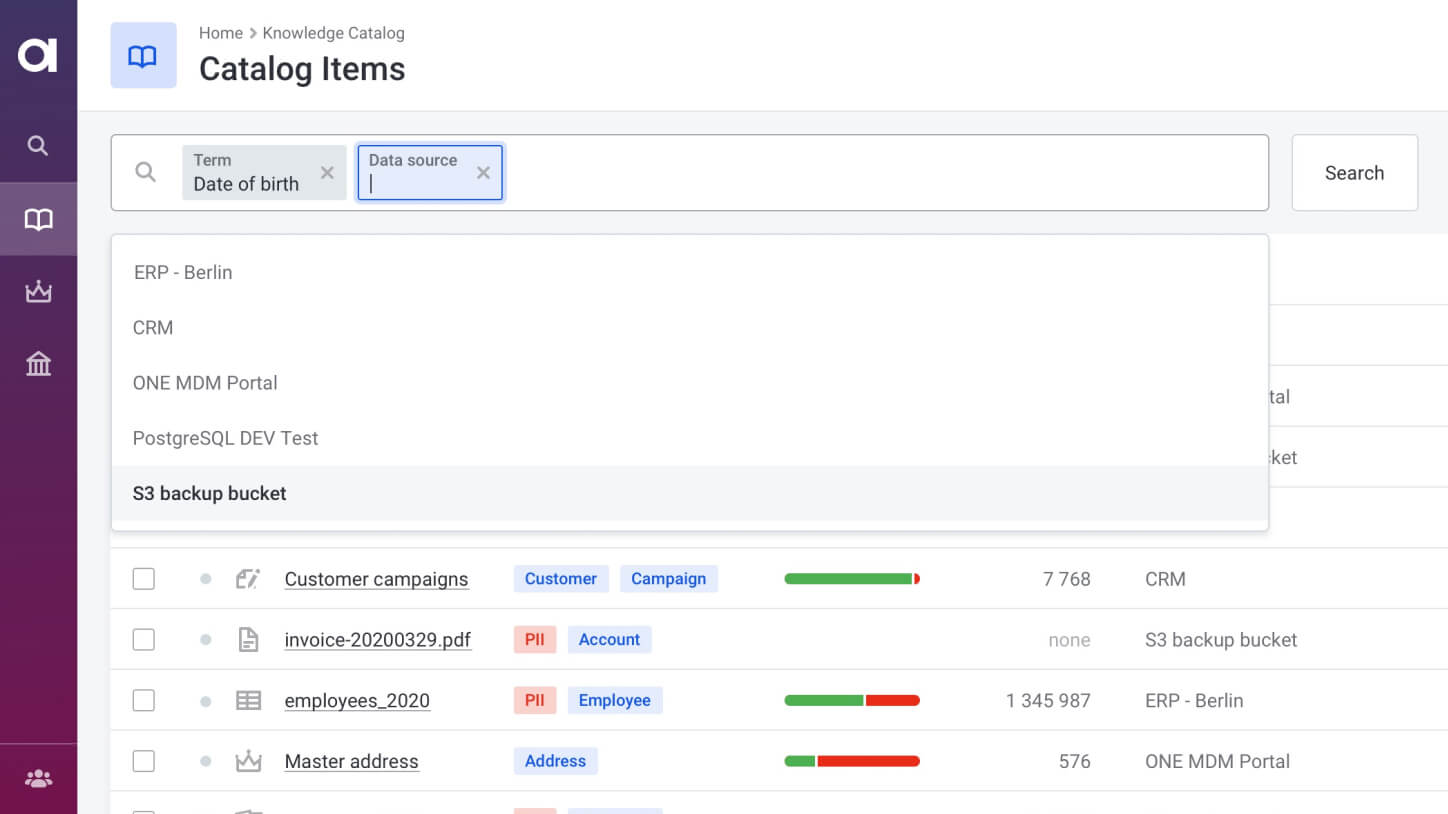
Search for data
Use filters and AI-augmented search to find data faster.
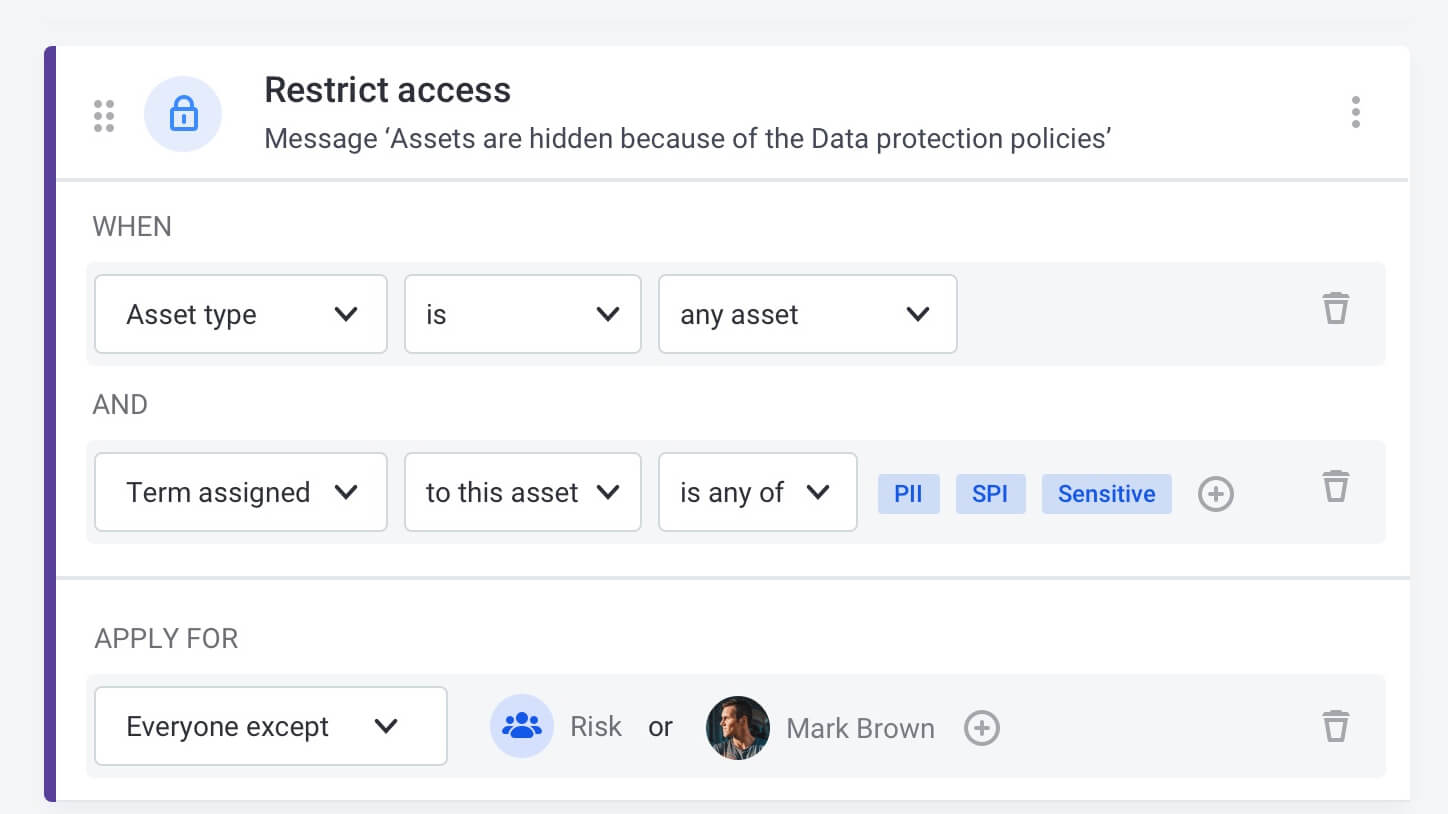
Automate sensitive data protection
Mask or hide sensitive data according to centrally defined policies.
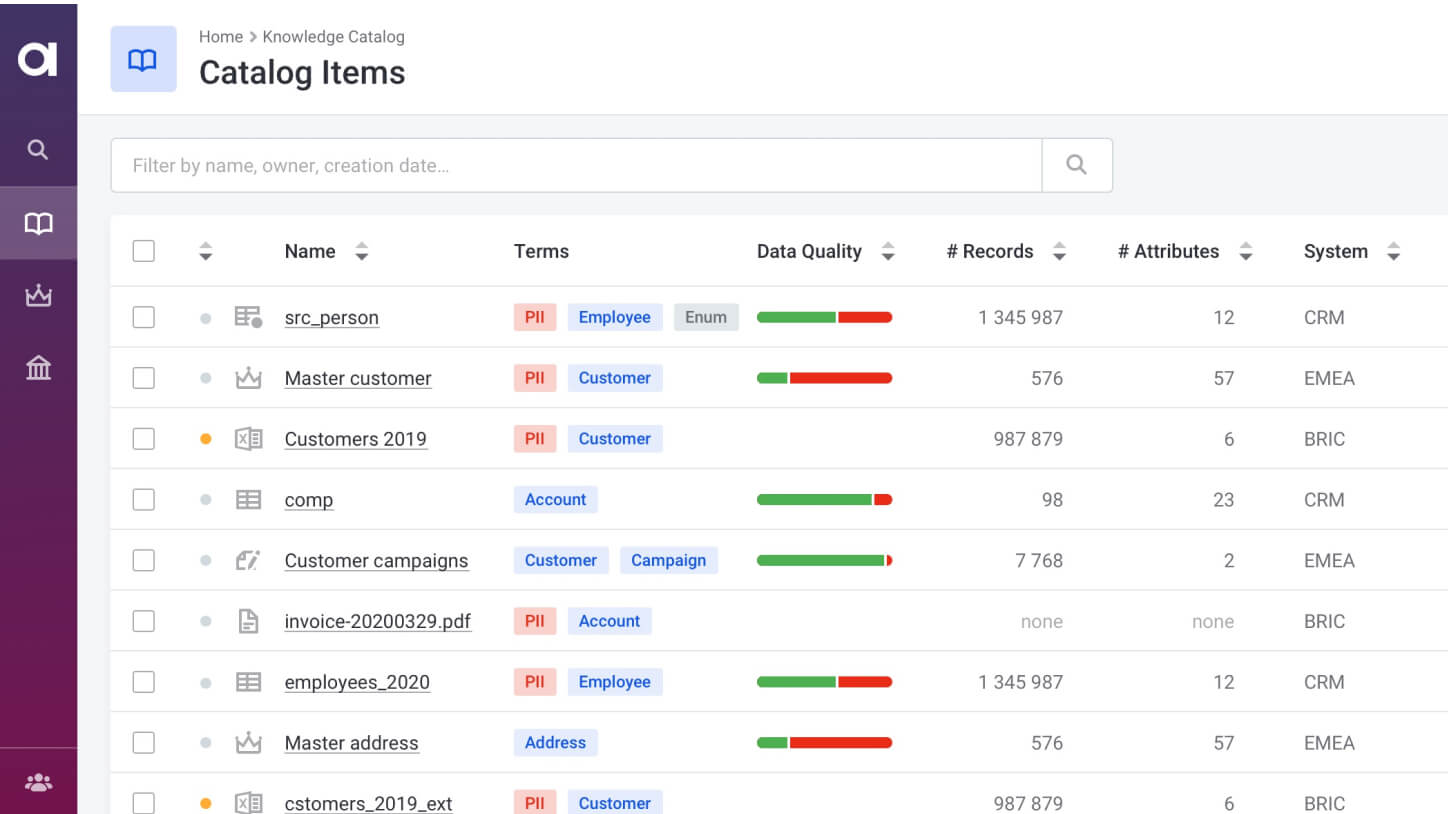
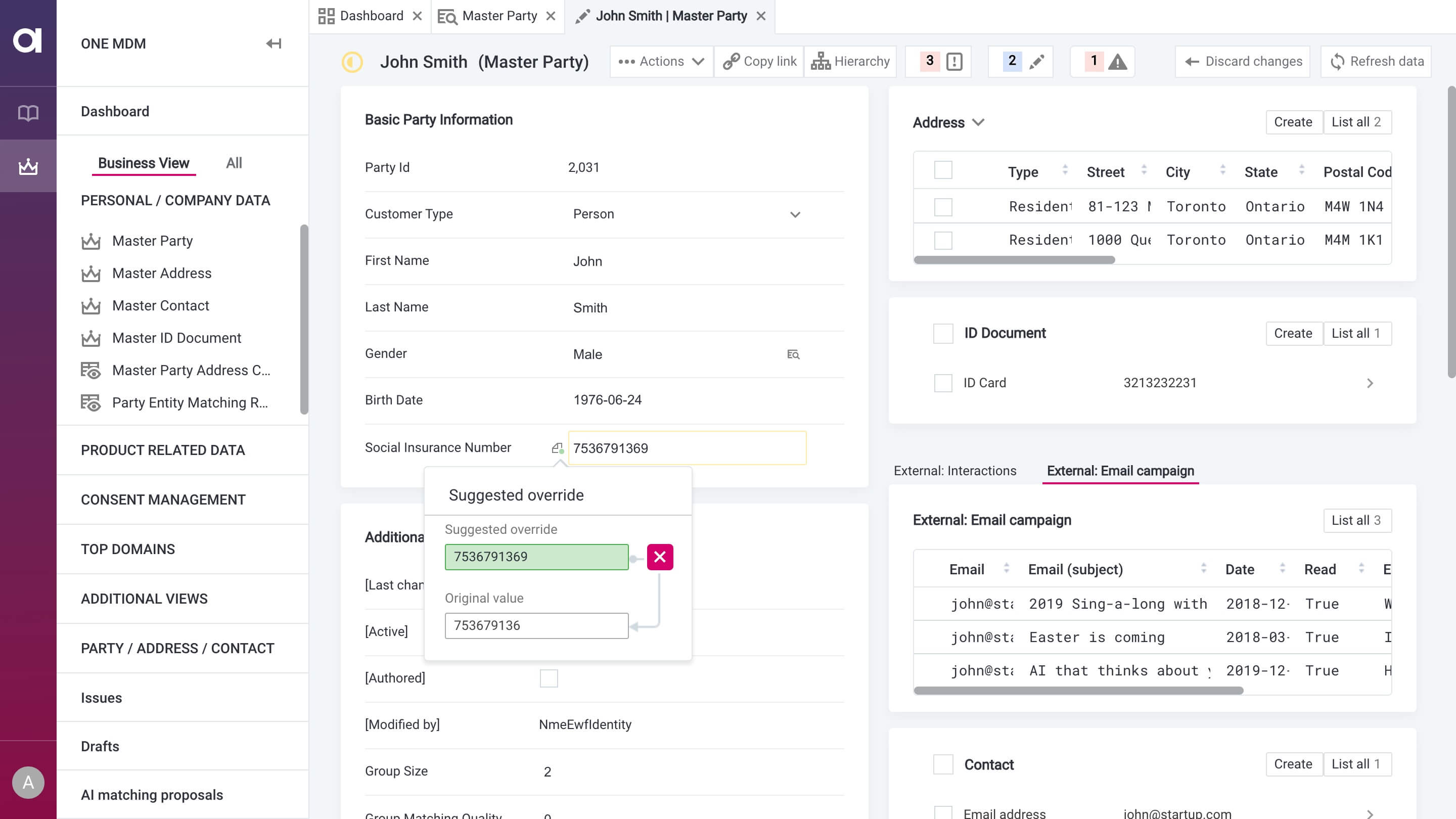
Ensure data quality on any data volume, reliably and without code
Easy to configure transformations
Configure transformations and add them to a common rule library. The re-use them on any new source you add and launch on a big data processing platform of your choice. No coding.
Automated data load monitoring
When you load data to your data lake, it is automatically monitored for anomalies and data quality issues.
Share business rules and transformations between teams
With Ataccama ONE, rules and transformations are data source-agnostic, so you can freely re-use them.
Best of all, run processing directly on the data lake
Ataccama ONE integrates with industry-leading big data clusters to ensure parallel and scalable data processing, including streaming.
At the same time, your data stays in the data lake and your organization stays compliant with data residency regulations.
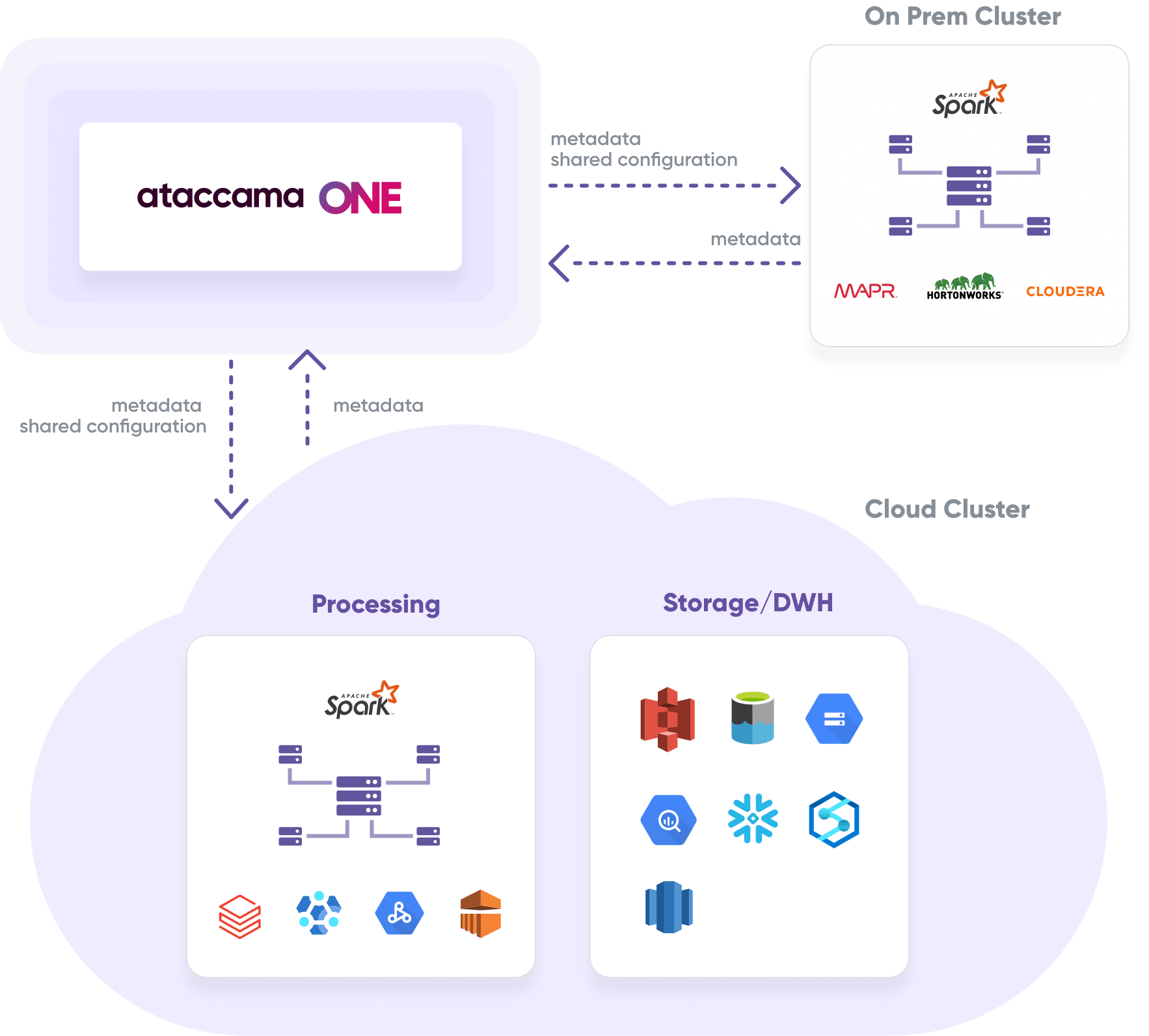
Here is how enterprises harness big data with Ataccama
1.5 billion records in 99 seconds
That’s how fast X5 Retail Group check product master data on demand on their data lake for product innovation
Millions in unpaid balances
That’s how much First Data (now Fiserv) uncovered thanks to data cleansing and enrichment in the PoC phase.
Learn more110 billion records
That’s the size of data that this American F&B retailer processes with Databricks on Azure Data Lake and catalogs in the Ataccama ONE Data Catalog.
2 person days a week
That’s how much analyst and DevOps time this American F&B retailer saves thanks to automated cataloging and monitoring of their data lake.
All the tools for data governance in ONE platform
Schedule a demo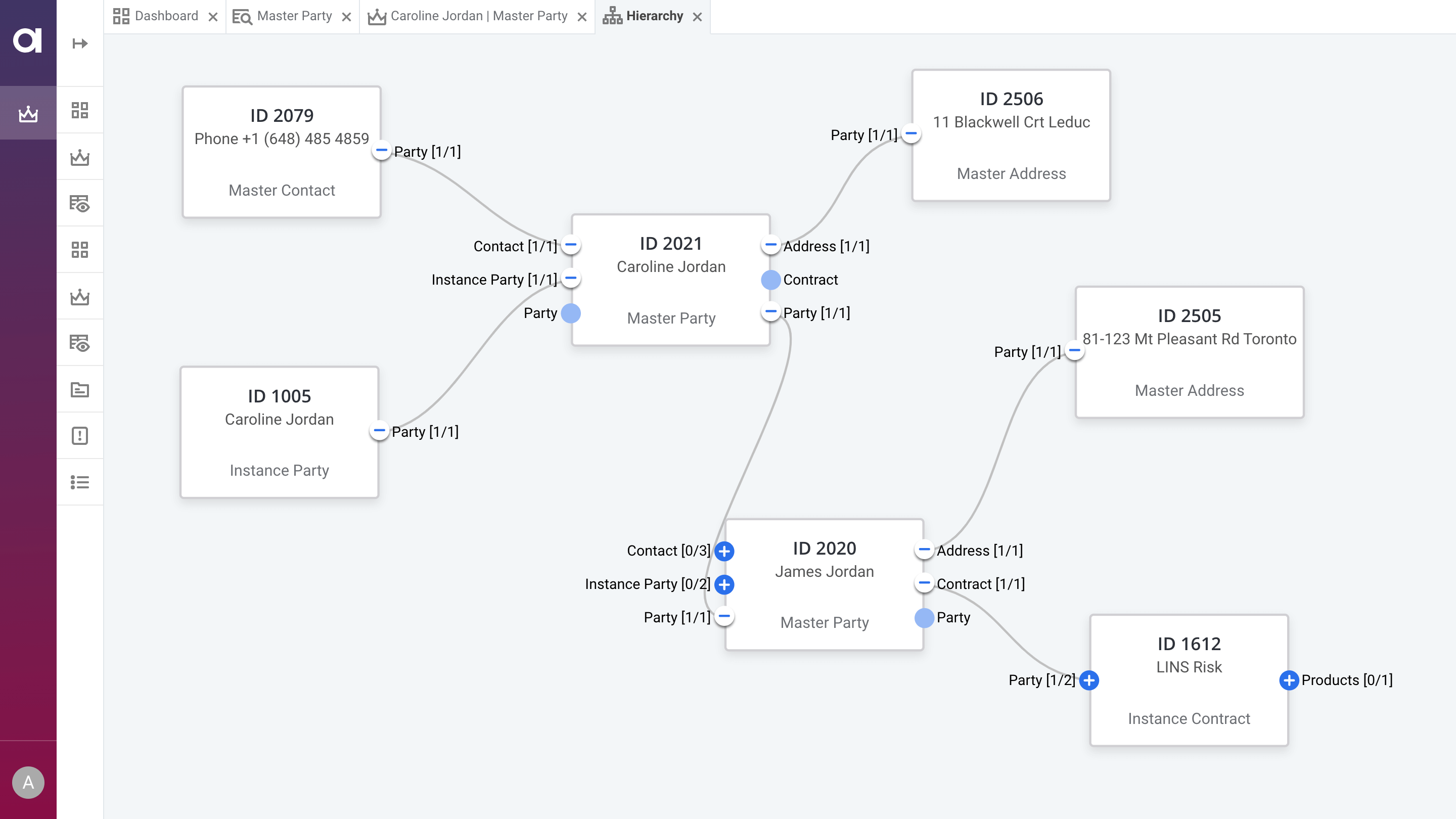
Just pick a timeslot.
Fast and easy.
Big Data Management Resources

4 Reasons Your Data Lake Needs a Data Catalog
Data lakes contain several deficiencies and bring about data…
Read more Discover the Ataccama
ONE Platform
Ataccama ONE is a full stack data management platform.
See what else you can do.



