See the
platform
in action
Gartner featured data fabric on both of its latest lists on top trends among the data community:
Coincidentally, it’s been moving up Gartner’s hype cycle for emerging technologies. Allied Market Research expects the data fabric market to more than triple in size between now and 2026 and cited a “rise in need for business agility and data accessibility” as one of the top impacting factors.
So what’s all the hype about?
What is a data fabric in simple words?
A data fabric is a data management solution design that connects all data sources and data management components to provide frictionless access to enterprise data to all consumers.
Within the data fabric, you’ll find all the fundamental functions of any data management framework such as data quality tools and a data catalog. However, they’ll be stitched together by metadata that result in synergies to create a user-friendly and predominantly autonomous enterprise-wide data coverage interface.
Data fabric definition
Since data fabric is a bit of a complex concept, providing a more formal definition might go a long way towards understanding it in greater detail.
First, let’s look at two of our favorite formal definitions from other resources.
"A data fabric is an emerging data management and data integration design concept for attaining flexible, reusable and augmented data integration pipelines, services and semantics, in support of various operational and analytics use cases delivered across multiple deployment and orchestration platforms."
From Gartner’s Demystifying the Data Fabric
"Conceptually, a big data fabric is essentially a metadata-driven way of connecting a disparate collection of data tools that address key pain points in big data projects in a cohesive and self-service manner."
From Data Mesh Vs. Data Fabric: Understanding the Differences by Alex Woodie
A Data fabric involves different sources and types of data being connected together with methods for accessing them. It is an integrated, semi-autonomous layer that will span across all of your data platforms to perform quality checks, map data, perform continuous analysis, and several other processes. All of this is driven through metadata which the fabric uses to recognize patterns, make autonomous decisions, and construct data flows.
What makes a data fabric a data fabric is how these components interact with each other and exchange metadata, which is a primary driver of automation.
A data fabric can also analyze how your organization uses and accesses data and can streamline processes for future inquiries, even predicting what a user wants to do before they enter a request. This learning mechanism also helps the fabric access data you might not have been aware of, or was too low quality and presents it to users ready for business exploration.
Why do we need a data fabric?
Now that we understand the concept of a data fabric, you’re probably wondering why it’s necessary. Organizing your data systems in this way allows for several advantages and benefits that having separate data management systems won’t provide you. Let’s look at all the reasons why you need a data fabric.
Manual and lengthy processes to get data
One of the best features of data fabric is that it delivers all of your data to you on a silver platter. Combining the capabilities of a data catalog, data integration, and data profiling creates an easy mechanism to find and access high-quality data.
Without it, you will have to dig through your systems to find data manually. Once you find it, you won’t be able to guarantee that it’s high quality or even the exact data you’re looking for without several extra steps and tons of legwork like writing code to find the data or needing to profile the dataset before you can use it.
Catalogs are great but don’t deliver data
If your company already has a data catalog, you might think you don’t need a data fabric. Data catalogs are connected to your data sources and discover relevant metadata from them. However, while data catalogs can deliver that metadata in an easily consumable way, they cannot deliver data the way a fabric can.
That being said, data catalogs are an important part of a data fabric architecture. Read on to learn more.
More and more data sources
As companies expand their data collection networks and tap into more and more data sources, the job of integrating data and managing metadata grows exponentially complicated. Eventually, companies realize they are impossible to perform manually.
Data fabric components
Since a data fabric is a design concept, learning about its components might help you better understand the framework as a whole. Here are six components part of the formalized data fabric architecture.
Data catalog
The data catalog connects to all of the important data sources in your organization and captures metadata from them. It’s arguably the most critical part of the data fabric because metadata powers much of the automation that the data fabric delivers.
It’s important to note that you need a current self-driving data catalog that automates metadata discovery and ingestion. In other words, when you connect a new data source to your data catalog, the AI will reuse the knowledge it has about the existing data sources to infer metadata about the new source. For example, it will suggest business terms to label technical attributes.
Knowledge graph
The knowledge graph stores all of your metadata and relationships between them, not just metadata about data sources (which are stored in the data catalog). Users can take advantage of this to better understand data and metadata. It’s also used by the recommendation engine (more on that below). Knowledge graph allows both users and machines (i.e., recommendation engine) to consistently explore relationships between all the metadata entities (regardless of the source).
Metadata activation
Metadata activation means using existing metadata and inferring new metadata from it. Some examples are profiling data, generating statistics, evaluating data quality, and performing data classification. Activated metadata is saved back to the knowledge graph, further extending previously captured information.
Recommendation engine
The recommendation engine uses all the metadata from the knowledge graph (including the activated metadata, technical metadata, catalog metadata, etc.) to infer more metadata or recommend how to process your data.
The recommendation engine performs three main types of tasks:
- Delivery optimization: it will suggest delivery models, optimize scheduling, and suggest data transformations.
- Metadata inference: it will find new relationships, perform data classification, and apply data quality rules — all as suggestions for business users.
- Anomaly detection: it will detect anomalies in data quality, data structure, or data delivery and alert stakeholders.
Data preparation and data delivery
The data fabric enables users and machines to consume data and metadata. Users can find and use data assets in the data catalog and transform (prepare) data in a self-service way. Machines can request and receive data via APIs.
The data fabric understands the structure of data (through metadata in the knowledge graph) and the intent of the data consumer. This enables the fabric to apply or suggest different data preparation or delivery types based on all the metadata and intent available. For example, it might suggest denormalized data for a report but normalized data for MDM.
The fabric should also simplify data delivery (or providing) by pre-configuring data output endpoints:
- Automatically generating APIs
- Letting users re-use existing data providing pipelines
Orchestration and data ops
Data fabric architecture requires components to optimize data delivery. This means having robust data processing engines close to data sources that can deliver data in the fastest way possible. One other requirement is adherence to Data Ops principles, such as reusability of data pipelines.
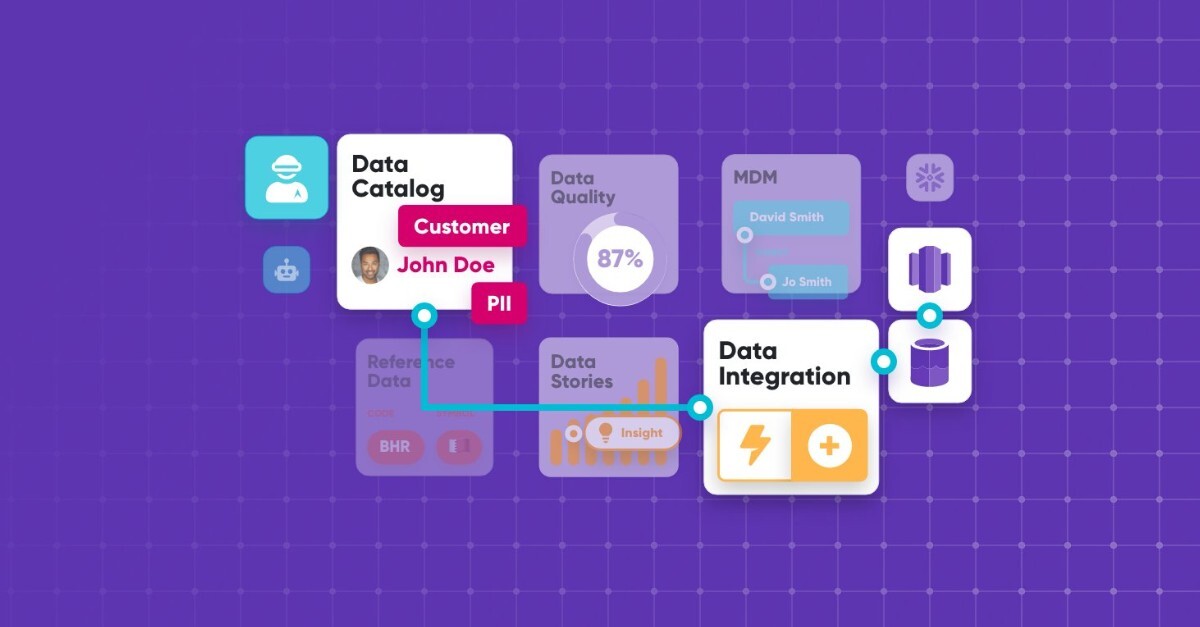
How does the data fabric work? The components in action
The section above describing the components of the data fabric might have already given you a good idea about how it works. However, you can have all these components and still not have a data fabric. You might find the illustration below helpful in understanding how these components interoperate.

Something better than a data fabric?
Data Quality Fabric embeds data quality services at all stages of the data life cycle.
Read the primerWhat are the benefits of the data fabric?
Keeping in mind the components and necessity of a fabric and its unprecedented automation powered by metadata, it provides businesses with several benefits that make it one of the most appealing design concepts for a data system.
Faster and easier access to data
As we already know, data scientists and consumers spend an alarming portion of their time gathering and preparing data for analysis. A data fabric enables self-service data consumption for anyone who needs it at your company, regardless of their skill sets. It creates a single point of access connected to all the company’s source systems, so users don’t need to hunt down the data they need, making it easier to understand the data and its origins.
Simplified data privacy and data protection
While Data fabric can provide you with faster access to your data, that comes with new risks as it exposes you to data leaks and unnecessary exposure to PII. However, the self-maintaining metadata collected by your fabric can help prevent these issues through automatic policy mapping and enforcement, allowing you to implement protocols and policies to protect your data. It can even mask/redact data or deny access to certain data attributes, rows, or even some metadata, ensuring only the right people will have access.
Massive maintenance and configuration time savings
By automating metadata management, data integration, and other processes, the data fabric dramatically reduces the time needed to configure and maintain your data platform. Think about how much time self-maintaining metadata and reusable data pipelines will save for your data engineers, data scientists, data stewards, and other SMEs.
How to implement a data fabric?
Data fabric design includes many different components, and you might be wondering where you should start. As you might have noticed above, metadata is the main resource that enables the automation of the data fabric. With that in mind, we suggest that you start with metadata management. If you don’t have a metadata management solution, set one up. Modern data catalogs give you a user-friendly way to implement it.
Some next steps:
- Implement a data quality solution that connects to the knowledge graph and uses its metadata to create data quality jobs.
- If necessary, implement a data integration component.
- Implement a self-learning recommendation engine that monitors the whole data fabric.
- Implement a metadata-driven data preparation and provisioning solution.
Adding more details is beyond the scope of this article. Each organization is different, so we suggest you talk to an expert.
Have a question? Speak to our industry expert.

Frequently asked questions
The section below should clarify any confusion about the differences between Data Fabric and other essential terms in data management.
Data fabric vs data virtualization
Data virtualization is one of the styles in which data fabric can deliver data. Data fabric goes beyond data virtualization in its ability to integrate and provide data in other styles and its ability to change and construct data views based on new metadata with minimal configuration.
For example, if a new data source is cataloged, its metadata will be automatically considered when providing data. Data fabrics can also use the information they learned from previous sources to accommodate new ones better as they’re introduced into the system.
In short, data virtualization provides a singular view of a company’s data sources, aiding in their analysis. Data fabrics are capable of this and much more, especially in terms of automating these processes, meaning that virtualization can be seen as a supported metadata delivery mode of a data fabric as opposed to an alternative framework.
Data fabric vs data integration
Unlike data virtualization, data integration actually combines data residing in different sources to provide users with a unified view of their datasets. Since data fabric connects multiple data sources into a single metadata-driven data providing layer, data integration is one of the main features of the data fabric.
Data fabric automates data integration by dynamically generating data integration pipelines whenever they are necessary to deliver the correct data to a requesting data consumer.
Data fabric vs data lake
A data lake is just a place to store data. A data fabric can access data in these data lakes and connect it to the rest of your data management and data analytics systems.
Data fabric vs data mesh
Data mesh is a fundamentally different approach to connecting data systems within one company. While data fabric builds a single layer of data across all your systems, a data mesh involves distributed groups or teams handling different parts of the data framework and collaborating through common data governance principles.
There are also ways to combine the two approaches, connecting systems through a fabric and still having distributed responsibilities like in the mesh. You can read more about the key differences here.
Build your data fabric with Ataccama
We have built data fabrics for clients like T-Mobile, Canadian Tire, Fiserv, and others.