What is a data mesh?
Data mesh is a new data management architecture that has gained a lot of popularity in recent years. It can bring greater stability and efficiency to a company’s data. However, it’s crucial to fully understand it, its advantages, and the necessary considerations before deciding what is best for your company.
What is a data mesh
The data mesh is a decentralized architecture and governance concept that puts the responsibility for data on the teams that produce—and actually own—the data. For example, financial team members would be responsible for the data in the financial domain. There will be no centralized ownership of data. Instead, each team will monitor their data, analyze, and transform it.
While there won’t necessarily be centralized governance rules for the entire organization, each team will prepare its data in such a way that, if another branch or department needs it, it is ready for them to work with. This allows the data mesh to distribute ownership without having data become siloed.
The pillars of data mesh
Still not sure what it means to have a data mesh? Maybe it will be easier to understand if we break it down further. 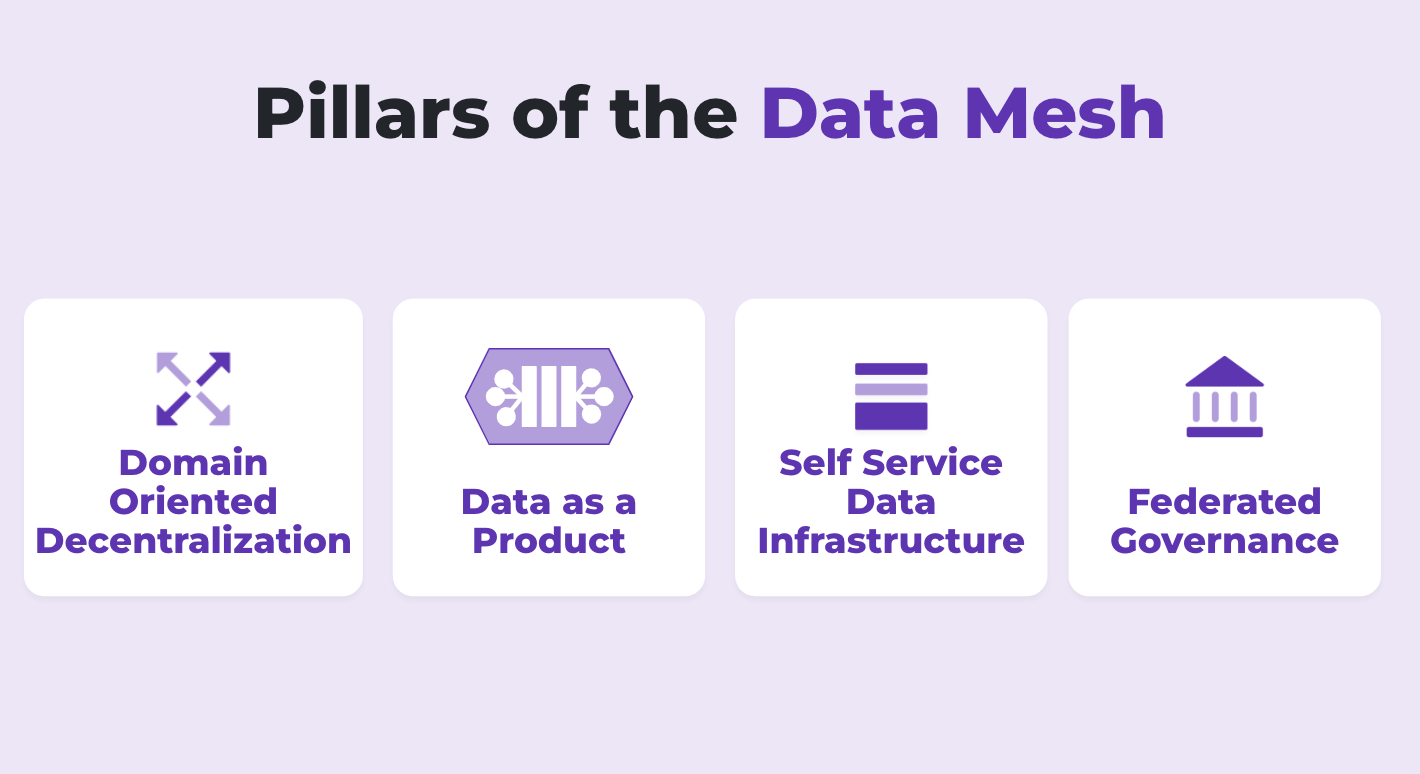
Domain oriented decentralization
The objective of this principle is to put the responsibility for data on teams that generate and own that data. Instead of the current status quo: giving the responsibility for data to “external teams” of data engineers and DWH teams that would ETL that data to a central data warehouse or data lake.
The people (data domain teams) working with the data (entering it, profiling it, sharing it with the organization, etc.) should take full responsibility for keeping their data up to company standards, usually by creating data products.
While the structure of these teams can vary depending on the domain, team, and organization, they will almost always have someone in the “data product owner” and “data product developer” roles. A data product owner is responsible for providing measures that guarantee data is delivered as a product. A data product developer is responsible for constructing, monitoring, and serving the data products — more on data products below.
Data as a product
Data as a product is a principle that forces domain teams to apply product thinking to the data they own, i.e., to ensure their data is usable. The result of applying this principle is creating, owning, and maintaining data products everyone will love. That, one could argue, is the alpha and omega of the data mesh, and not only… Here at Ataccama, we think companies should think about their data as a product regardless of whether they’re building a data mesh organization.
So what characteristics allow you to consider a regular data set a “data product?” According to data mesh founder Zhamak Dehghani, they are the following:
- Sharable and discoverable: publish data products for the rest of the organization to use.
- Self-describing: data products should be very well defined.
- Addressable (same location, predictable in the future): data products should be able to be accessed.
- Trustworthy: data products should have high data quality management.
- Interoperable: data products should work with other data products.
- Secure: protected from unauthorized access.
To achieve all these characteristics, data products need to have all of the following built-in features:
- A way to extract new data from sources
- A way to output data in a well-defined interface
- The code it needs to run to transform the data
- Storage infrastructure
- Control ports where you can call the data product, run transformations, and request the data
“[They should have the] ability to run independently without relying on other data products or infrastructure. This unit should be built, maintained, and deployed as one component.”
– Zhamak Dehghan founder of Data Mesh
To summarize, a data product is a way to describe a dataset that is entirely up to organizational usability and governance standards and ready for use with no additional work required. This way, regardless of where the information is stored or who’s responsible for it, everyone at the company will be able to use it. All of the company’s data will be accessible upon request without any additional effort or preparation.
Self-service data infrastructure
To maintain the data mesh’s decentralized nature, domain data teams must be autonomous in building data products. For that to work, data teams need to have data infrastructure as a service. This infrastructure should be easy to use, meaning instead of teams building their own, they have all the tools and technology they need to build a data product.
It goes against the data mesh concept to require teams to use anything they don’t want to. The mesh relies on most of them using the infrastructure by choice, so companies need something they enjoy, are familiar with, and can see the value in using the same standard as other teams in the organization.
Data mesh structures this infrastructure via three planes:
- Data infrastructure plane
- Data product developer experience plane
- Data mesh experience plane
First layer: data infrastructure plane
Providing the underlying infrastructure needed to build, run, and monitor your data products.

Second Layer: data product developer experience plane
Abstraction of data infrastructure designed to support the data product development journey — provisioning things like output endpoints, data quality, versioning, and security for data products. This is supposed to work by data product developers being able to use easily — or request (again, in a self-service manner) —these capabilities and the underlying infrastructure will provide that functionality.

Third Layer: mesh experience plane
Browse existing data products, ensure documentation is in order, and look at how data products relate to each other — more convenient access to capabilities for data citizens.

Federated governance
Since this is a decentralized concept, the governance principles that apply to data products can vary from department to department. However, risks or “governance debts” can arise if teams have no common ground to stand on. Some governance problems that data mesh teams risk running into are:
- Metadata and cataloging standards differ
- Missing/incomplete documentation
- Availability windows
- Low quality/different quality standards
- Incompatible formats
- Different security standards and policies
To mitigate these risks, companies should adhere to the concept of global governance based on a few open standards. Teams will immediately understand the advantage of having some principles in common throughout the organization.
Data mesh, therefore, relies upon teams following a set of global principles for data governance, which should be documented as in any data governance program. However, to simplify the enforcement of these policies, data mesh commands to automate, automate, automate. And the way to do that is, of course, to embed them into processes. For example, automate data quality processing, data masking, or the assignment of workflows for data access requests.
Data mesh benefits and considerations
Before you decide data mesh is suitable for your business, please weigh the following benefits and considerations.
Benefits
Produces motivated and efficient teams. Data domain teams focus on a specific domain and have both the knowledge and technical skillset to be autonomous. Freedom to use the tools of your choice and Independence from vigorous governance enforcement encourages them to take more ownership and become more motivated.
Accelerates delivery of data products. For all the reasons mentioned, these motivated and efficient teams are better at creating data products.
Reliable and extendable. As organizations grow, the self-service infrastructure makes it easier to onboard new users, and shared governance rules are clearly documented, allowing them to expand without having to constantly rework administrative principles.
Considerations
Governance debt (if standards are not enforced). If your global governance standards are too loose, you can end up with some of the governance debt problems we mentioned earlier.
Possibility to recreate silos. The worst-case scenario for a data mesh is that no one follows governance guidelines and you end up with data products that aren’t interoperable, discoverable, or addressable – data silos. You must maintain governance standards between all domains to avoid data siloing.
Data mesh vs. data fabric
Data fabric is another emerging data management framework that has made a lot of noise in the last 12 months. On the surface, it might seem that it is a competing concept for data mesh. But is it really so? The fact is these new blueprints are not mutually exclusive.
A data fabric is all about frictionless access to enterprise data for all consumers. It works by connecting all data sources, data management components, and data consumers into a unified system heavily driven by AI to automate data providing.
Data mesh, on the other hand (as we already discussed), is focused on producing high-quality data — data products.
If we combine these two we will get frictionless access to high-quality data. In essence, data fabric empowers data people to create great data products (while managing governance debt).
If you look closer at the self-service data infrastructure and federated governance pillars of the data mesh, you can see that a data fabric can be the layer that ensures them, with these specific characteristics:
- Global Governance
- Automatic Documentation
- Discoverability & Shareability
- Interoperability
- Efficient Processing
- Security
- Quality
Having these principles in place will allow domain teams to create data products which are:
- Easy to discover
- Easy to use & combine
- Trustworthy & documented
- Unburdened by provisioning
- Automatically enforced standards
- Fast to create
The bottom line is:
Data fabric empowers data people to create great data products while managing governance debt.
Build your data mesh with Ataccama
If you feel data mesh is the right architecture for you, Ataccama can help. We provide a unified data management platform, Ataccama ONE, for teams to build, publish, and discover data products.
Ataccama ONE comes with a data catalog, automated data quality solutions, MDM, and data governance seamlessly connected with shared metadata.
It easily integrates with your data landscape and can be deployed to any infrastructure. If you’d like to learn more, schedule a call with us.