Ataccama ONE Platform Overview
The ONE platform you need
Ataccama ONE unifies Data Governance, Data Quality, and Master Data Management into a single, AI-powered fabric across hybrid and cloud environments.
The Ataccama ONE platform gives your business and data teams the ability to innovate with unprecedented speed while maintaining trust, security, and governance of your data.
Learn ONE, know it all
A single, modular platform for all of your data management and governance needs.
Works with any data and big data
Our engine runs natively on your favorite big data platforms.
Designed for data people
Business and technical people have different needs. That’s why the user experience of Ataccama ONE is tailored specifically for:
Enterprise-grade platform
Built for mission-critical deployments in highly regulated environments.
Discover
Ataccama ONE
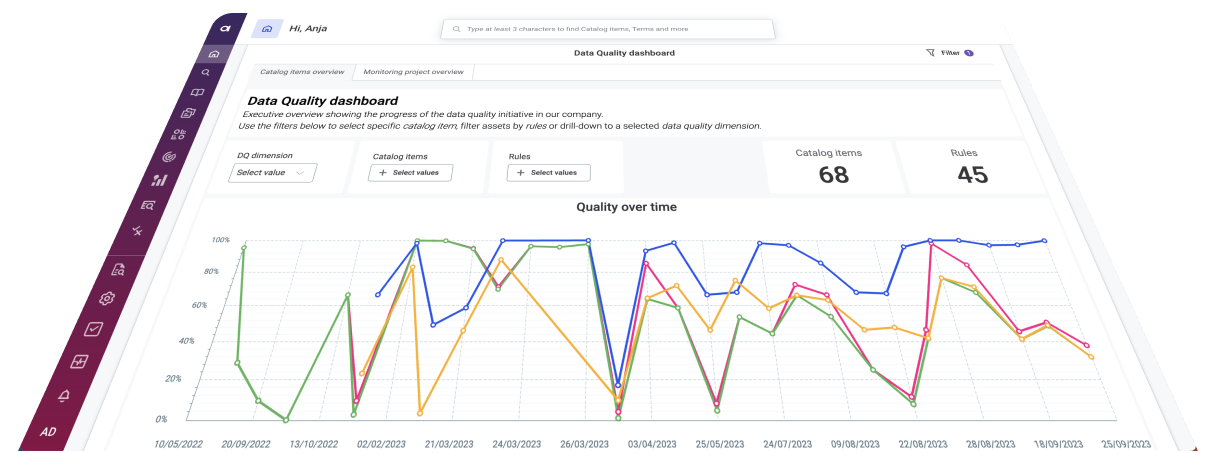
Data Quality
Ataccama ONE manages data quality automatically. Just connect your source.
Learn more about data quality
Automatic anomaly detection in your data on the fly.
Automated assignment of business rules for all data
Super fast data processing on any data.
Easily customize data quality rules without any coding.
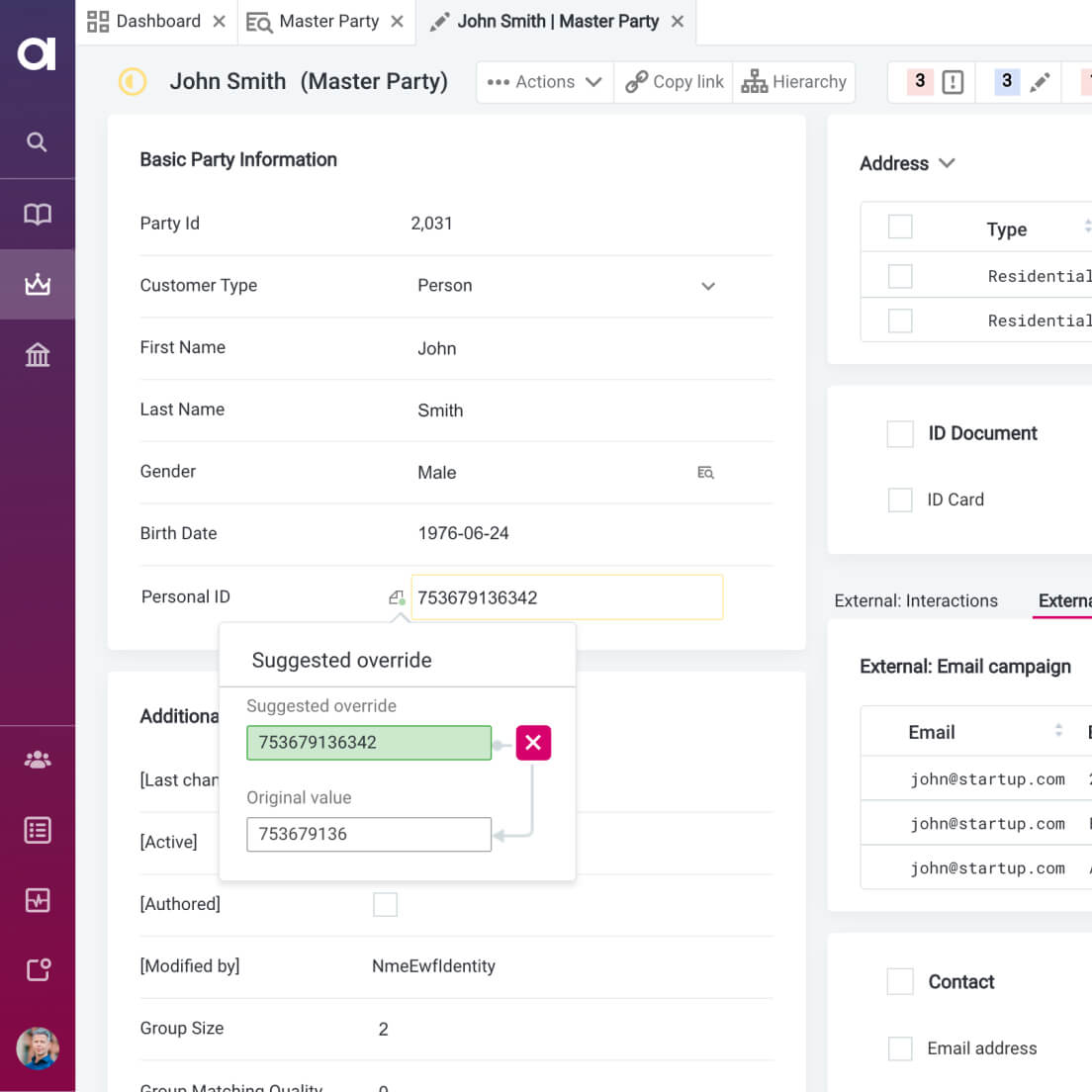
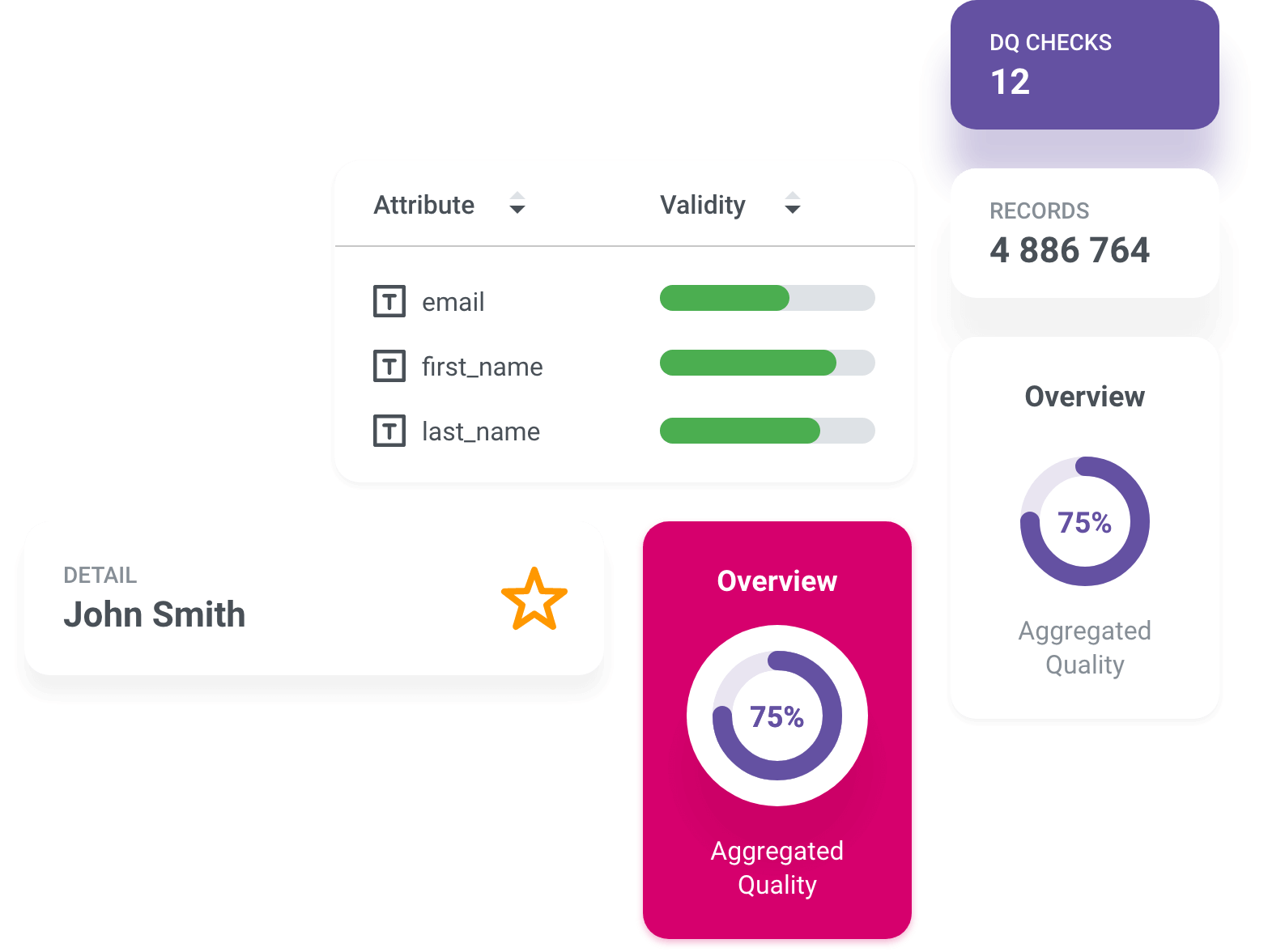
Master Data Management
Easily check the contents of a data set before using it.
Learn more about master data management
Rapid model development thanks to data discovery & profiling
AI-suggested matching rules
Built-in data quality processing
Feature-rich data steward web app
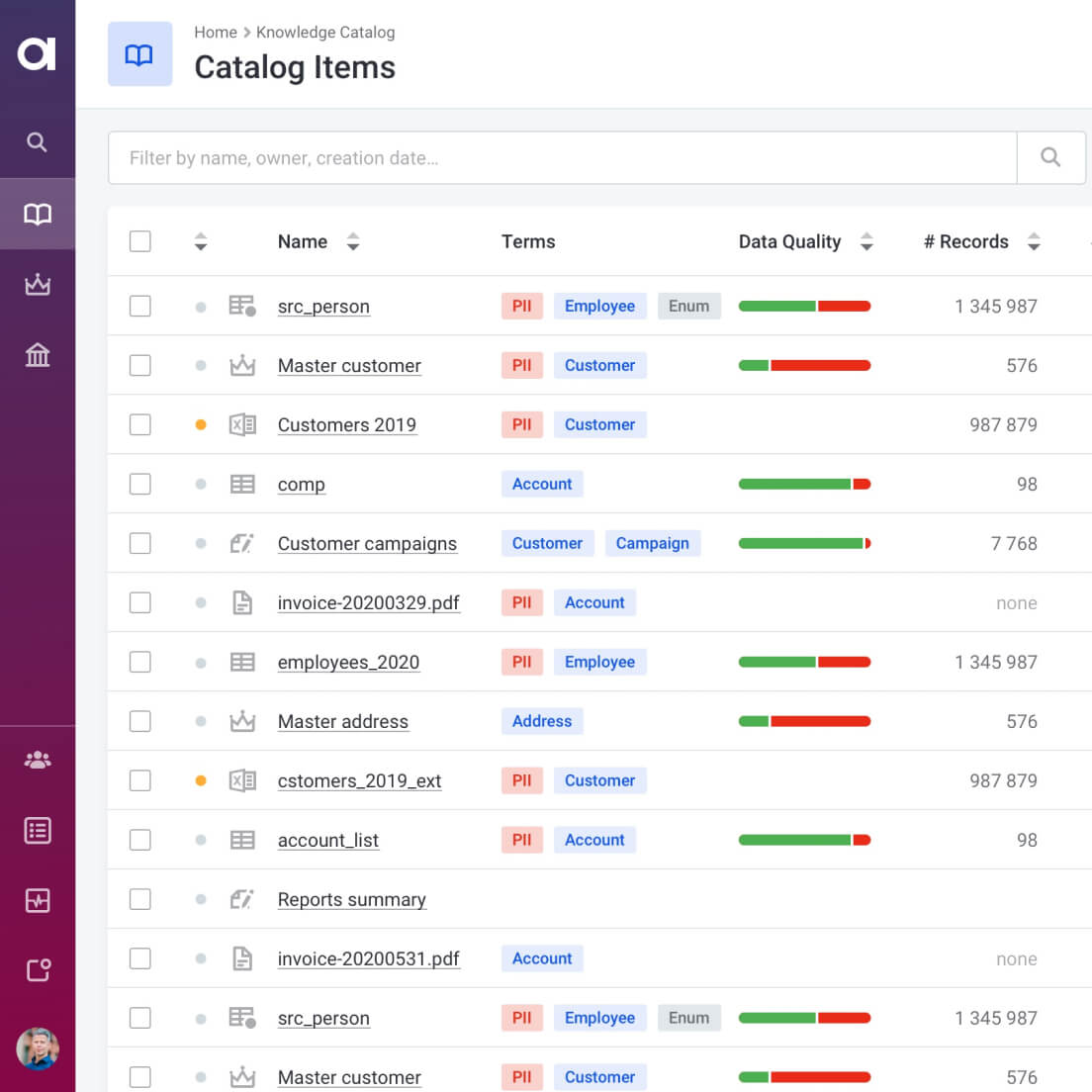
Data Catalog
The first fully automated Data Catalog.
Learn more about data catalog
Automated data discovery and change detection
Automated data quality calculation and anomaly detection
Collaboratively improve data assets with tasks, comments, and sharing features.
Create metrics, reports, and trusted data sets, or export data anywhere you want.
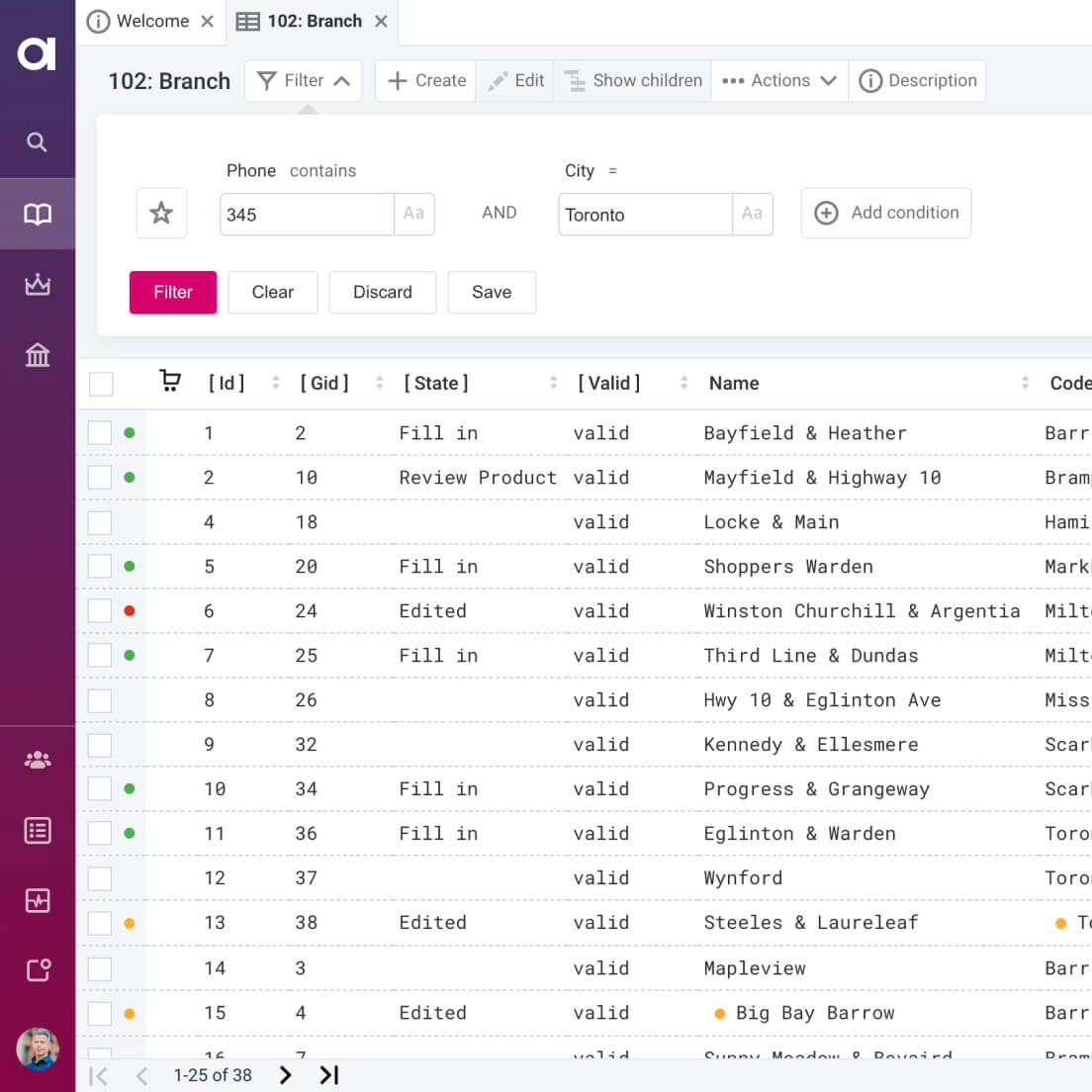
Reference Data Management
No more spreadsheets, back-and-forth emails, or SQL nightmares.
Learn more about reference data management
Manage all reference data in a single app
Provide valid reference data to systems and users
Ensure data governance
Get started fast and scale as you need

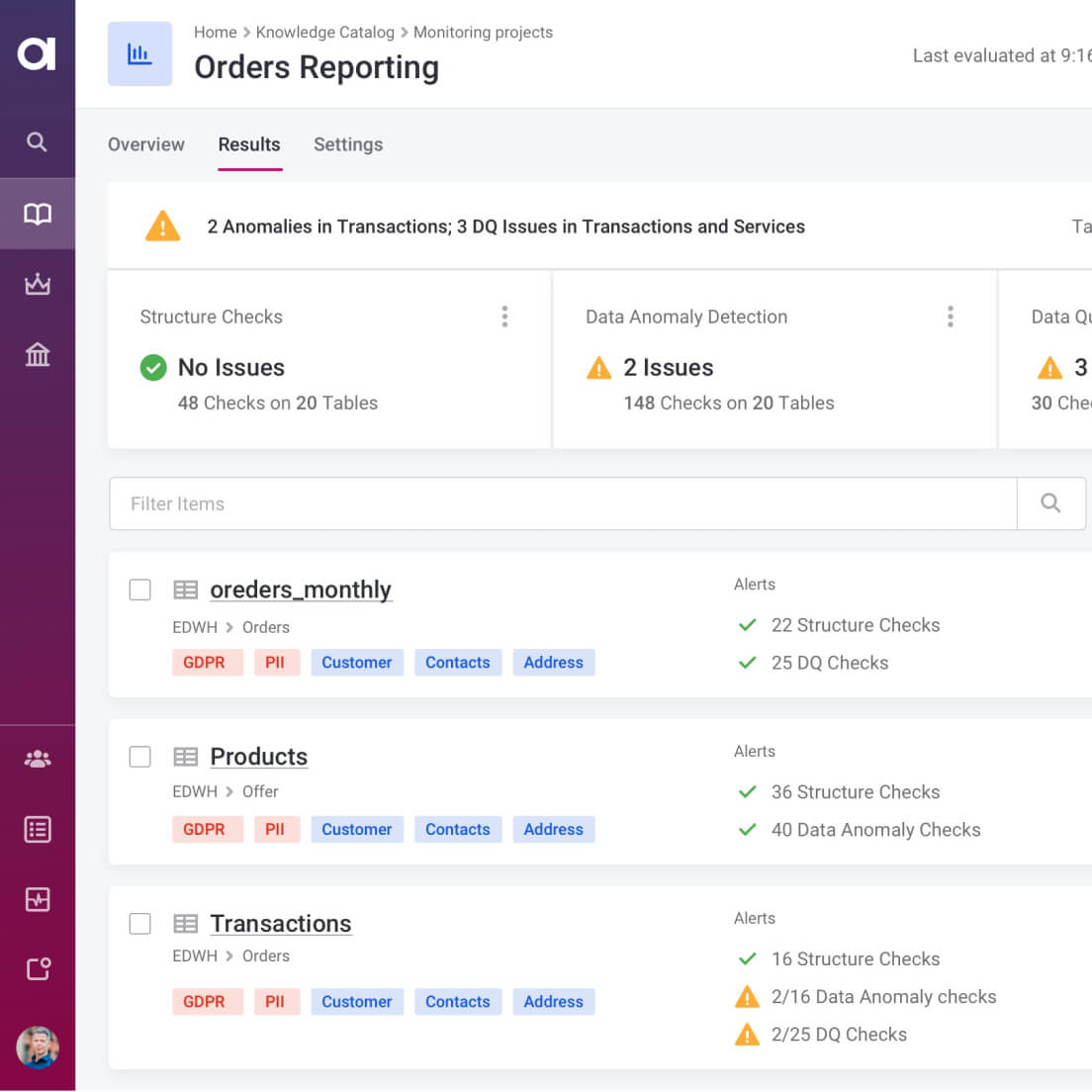
Data Observability
Get notified about issues in your data before they affect your business-critical systems.
Learn more about data observability
Understand what data you store in your business systems.
Experience automated data quality monitoring with rule-based controls and AI.
Get alerts for anomalies and data quality drops.
Monitor schema and data volume changes.
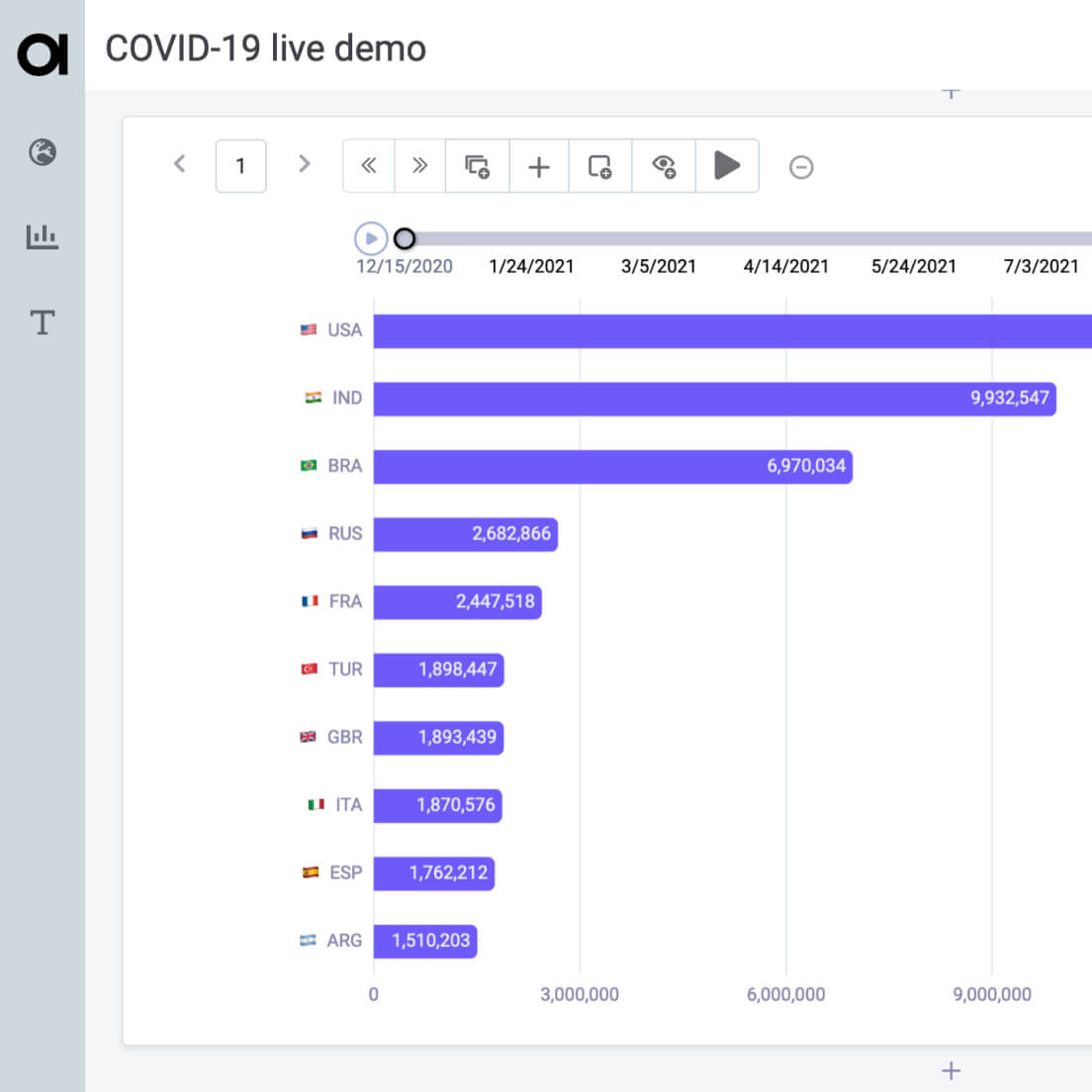
Data Stories
Make data graspable for everyone, present complex facts and wow all stakeholders.
Learn more about data stories
Work directly with data to present information
Choose from dozens of charts and highlight important facts
Keep your stories up to date
Share results with others with video exports and embeds