
AI is the new electricity – where is your data trust grid?
AI has been called “the new electricity” for its transformative potential across industries. Just as electricity revolutionized business a century ago, AI promises to illuminate every corner of the enterprise with intelligence. And we see it already happening… generative AI is no longer a novelty but a ubiquitous utility. It’s embedded in search engines, surfacing in CRM systems, answering questions in productivity tools. The question for executives is no longer what AI might do, but what data it will be allowed to touch. In that shift of focus lies both the real risk and the real opportunity ahead.
Enterprise data teams are navigating pressure on multiple fronts. The volume of data isn’t just growing, it’s compounding. By some estimates, the total amount of data created doubles every 3 years, pushing organizations from terabytes to zettabytes with little time to adjust. So do expectations that data can be shaped into something useful at pace, that it will hold up under scrutiny, and that it will support AI efforts without adding risk. The regulatory bar, meanwhile, is not static. Though, it rarely is.
Many organizations are rising to the challenge, but often with infrastructure that shows its age. And over time, confidence in the numbers can start to erode. It shows up quietly, in duplicate reports, in cautious queries, in AI projects that stall not because the models failed but because the data fueling them raised questions.
Yet the path forward is not out of reach. If AI is to become as integral to the enterprise as electricity, then the supporting grid, or the layer of trust that allows data to move cleanly and credibly across the business, needs to be treated as strategic infrastructure.
Hit the gas or tap the brakes? The executive dilemma
AI has a way of accelerating decisions that, until recently, could comfortably wait. While it brings urgency, it also brings uncertainty. There’s nothing especially new about the tension between speed and certainty, but AI has a way of magnifying it. It’s not so much a binary choice between momentum and caution, as it is a growing awareness, that the quality of your data will determine just how far you can go.
It wouldn’t be the first time technology moved faster than the infrastructure expected to keep up. A decade ago, the move was into data lakes where anything could be stored and, in theory, analyzed later. When that vision fell short, the conversation shifted to new ideas – data fabric, data mesh, and frameworks designed to bring order to the sprawl and make the whole ecosystem more navigable. Some gained traction, others stayed theoretical, but the core issue remained. Without shared standards or clear ownership, the lake didn’t sharpen understanding so much as blur it. Definitions slipped, duplicates spread, and what began as a solution to storage quietly evolved into a deeper, more persistent problem, not of scale, but of trust.
What began as a well-intentioned push for data democratization ended in disillusionment. And today, the difference is speed. An AI system won’t wait for human review or oversight. If it’s connected to an ungoverned data source, you might not realise there’s a problem until someone has already acted on a faulty, AI-generated answer.
Data quality powers trustworthy AI
The promise of AI may be dazzling, but its performance still depends on something far more mundane than advanced algorithms or powerful computers: it depends on the data it’s given. And this is where the conversation often goes quiet.
In reality, AI seldom fails because of flaws in its model; it fails when the data feeding it is stale, incomplete, or scattered across systems with murky ownership. Yet all too often, AI gets the spotlight as the innovation headline, while data quality remains buried in the appendix. That needs to change, because the infrastructure that makes AI useful at scale isn’t just silicon and servers, it’s trust.
Not “trust” in a vague philosophical sense, but something measurable and operational. It’s the trust that data is sourced, structured, and maintained correctly across the organization.
It’s the quiet expectation that systems agree on who the customer is, what the transaction means, where the figures came from. That the data used to train or trigger AI is current, consistent, and explainable.
Organizations serious about AI need to be just as serious about the infrastructure that supports it. Data quality and governance might not attract the same headlines as generative models, but they are the quiet systems that make reliable outcomes possible. Without them, speed alone doesn’t confer advantage; it just magnifies the consequences of getting it wrong.
Agentic data trust in action
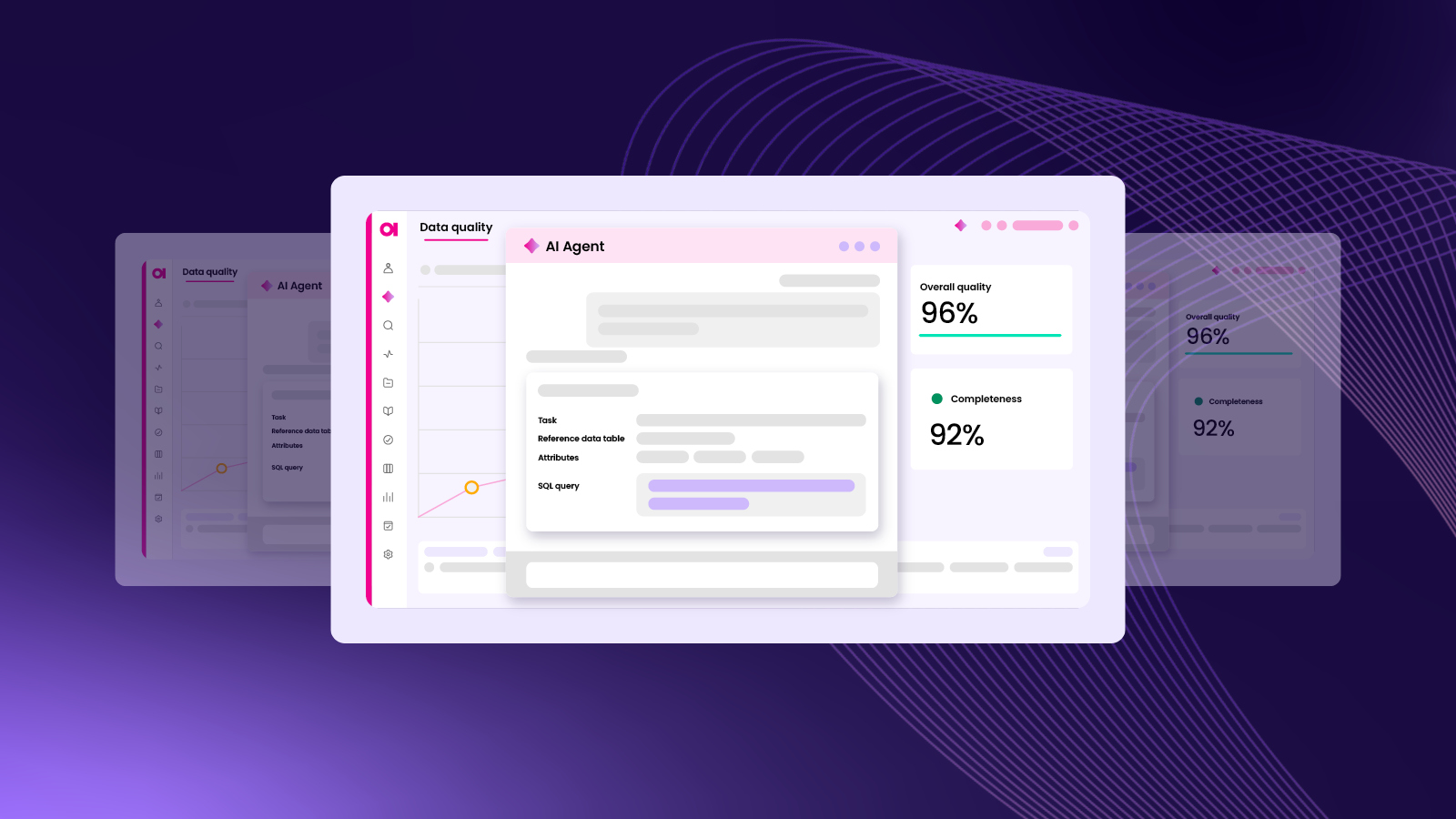
Most leaders know, in theory, what trustworthy data should look like. Far fewer have felt what a truly agentic data environment is like in practice. Ataccama’s (just launched) agentic data trust platform was built to change that.
It takes the concept of data trust and turns it into an everyday operational experience. In contrast to a patchwork of scripts, static reports, or after-the-fact firefighting, this platform delivers something more deliberate and continuous. It isn’t just a tool that flags problems after they’ve happened; it’s an architecture designed to prevent many of those problems from occurring in the first place.
Ataccama’s platform brings together functions that organizations already recognize as essential, data quality, observability, governance, lineage, master data management, and makes them work in concert as a single, coherent system.
That kind of cohesion matters. Trust in data rarely breaks in obvious places. It tends to unravel upstream, in ways that are hard to spot and harder to trace. Understanding where things go wrong (and why) requires context that spans systems, not just dashboards. It also demands the ability to step in with something more deliberate than educated guesswork.
A unified and agentic-by-design platform provides the end-to-end context to see not only the symptoms but the cause, and to address data issues at their source before they mushroom into bigger problems.
At the heart of this platform sits the ONE AI Agent, an autonomous worker that does much of the heavy lifting that data teams often wish they had more time for. It can identify where data quality rules are missing, generate the right ones, test them, and apply them across entire datasets in seconds. It understands context, from how the data is structured, how it’s used, to what matters in a given environment, and adjusts accordingly. Whether turning a plain-language prompt into a SQL query or coordinating a multi-step remediation workflow, it shortens the path from issue to outcome, with every step documented and easy to follow.
Tasks that might have taken ten minutes each, such as creating and applying rules, cleaning up tables, and assembling new data assets, now run in under one. Spread across hundreds of systems, the cumulative impact isn’t just efficiency; it’s about time reclaimed. In early use, some organizations have seen weeks of manual effort reduced to a few hours. Time spent on the core work of improving data has dropped by as much as 83 percent because the system is finally pulling its weight.
Turning trust into a strategic advantage
As AI becomes less a standalone initiative and more something expected to underpin day-to-day decisions, the organizations moving with the most clarity are those that treated the underlying data work not as technical debt to be managed later, but as a prerequisite for scale.
Not just infrastructure in the technical sense, but in the clarity, consistency, and governance of the data that flows through it. This isn’t a conversation about tooling or dashboards. It’s about whether the business can trust the information it runs on, and whether that trust holds up under pressure. For those looking to move beyond isolated pilots and embed AI at scale, that shift in posture is what will separate experimentation from execution.
Invest in the architecture, platforms, and processes that ensure your data is accurate, accessible, and auditable. Do this, and you can embrace AI’s breakneck velocity safely, turning speed into an asset rather than a liability.
At Ataccama, this philosophy of velocity with verification informs how we think about scale. In an AI-driven enterprise, success won’t hinge on how much data you have, but on how much of it you can trust. That kind of trust is entirely within reach, and the payoff, in agility, innovation, and competitive edge, is more than worth the effort.
Mike McKee
Mike is the CEO at Ataccama, appointed in August 2023, with 30 years of leadership in data- and AI-driven companies—most recently as CEO of Dotmatics and ObserveIT (now Proofpoint) and in senior roles at Rapid7 and PTC. A former pro hockey player and father of four, he still enjoys hockey, and being active with family and friends.







