Introducing Data Quality Gates – Real-time data quality in your pipelines
If you’ve ever seen an AI model produce predictions that made no sense, or had a compliance report collapse just before a board meeting, you know the cost of bad data. The trouble is that these problems are often invisible at first. Jobs finish successfully, dashboards update, tables refresh. Only later do downstream teams discover that the content is wrong.
Bad data still gets through, and it’s expensive
When bad data slips past checks, costs rise quickly. Invalid values can derail AI models, distort analytics, and trigger compliance failures.
- For CDOs, the risk is strategic: unreliable analytics, regulatory exposure, and decisions made with unreliable data
- For governance leaders, it shows up as missed SLAs, endless rework, and a backlog of issues that never quite clears.
- For engineers, it means reruns, broken pipelines, and quick fixes written in SQL or dbt.
Gartner estimates that poor data quality drains $12.9 million per year on average from organizations. Most of that spend goes not into prevention but into remediation and repair. And much of it is avoidable if issues are caught earlier.
Pipeline monitoring and quality validation
Observability tools play an important role in the modern stack. They keep data pipelines healthy by spotting schema drift, unexpected volume changes, or freshness issues. These signals are essential for understanding if a job is running as expected.
What observability does not check is whether the data matches the business definition of “fit for use.” A pipeline can deliver the right number of rows on schedule and still carry hundreds of invalid records, for example, risk codes that don’t match the official reference dataset, or customer records missing mandatory identifiers. These are the kinds of silent failures that surface only downstream, when the cost is highest.
That is why observability and validation need to work together. Observability confirms that the system is functioning. Ataccama Data Quality Gates bring that validation into the pipeline itself, ensuring that every record meets business-defined rules before it is used. Together, observability and DQ Gates give teams the full picture: healthy pipelines and trusted data.
Shifting data quality into the pipeline
The way to prevent late discovery is to bring validation into the pipeline itself.
Column-level trust, not just job success
Where observability asks “did it run?”, Data Quality Gates ask “is the data right?”
By applying governed rules inside data pipelines, engineers can check column-level values as records move through bronze, silver, and gold layers. This means catching invalid dates of birth, missing risk ratings, or noncompliant country codes before they contaminate downstream datasets. For regulatory reporting, this is critical. A job finishing successfully is not enough. Every record has to meet the rules before it can be used.
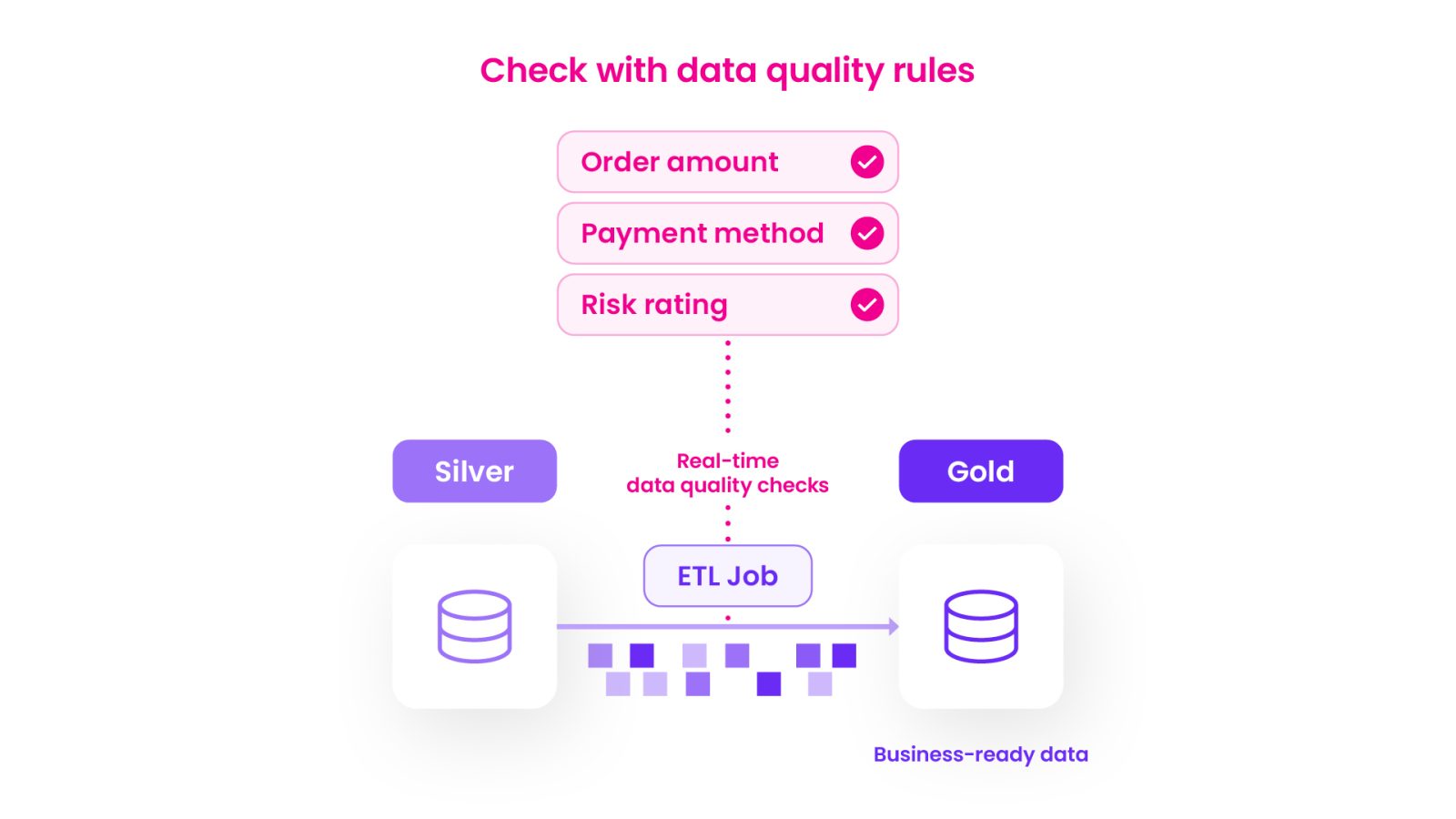
Validate the quality of the data inside tables by checking accuracy at the column level to ensure only trusted, business-ready data flows downstream.
Stopping problems from spreading
Inline validation changes the economics of data quality. Records are checked before they land in silver or gold layers. Invalid entries can be flagged, quarantined, or rerouted for remediation. Downstream systems only see trusted data. The result is fewer reruns, less rework, and lower operational cost.
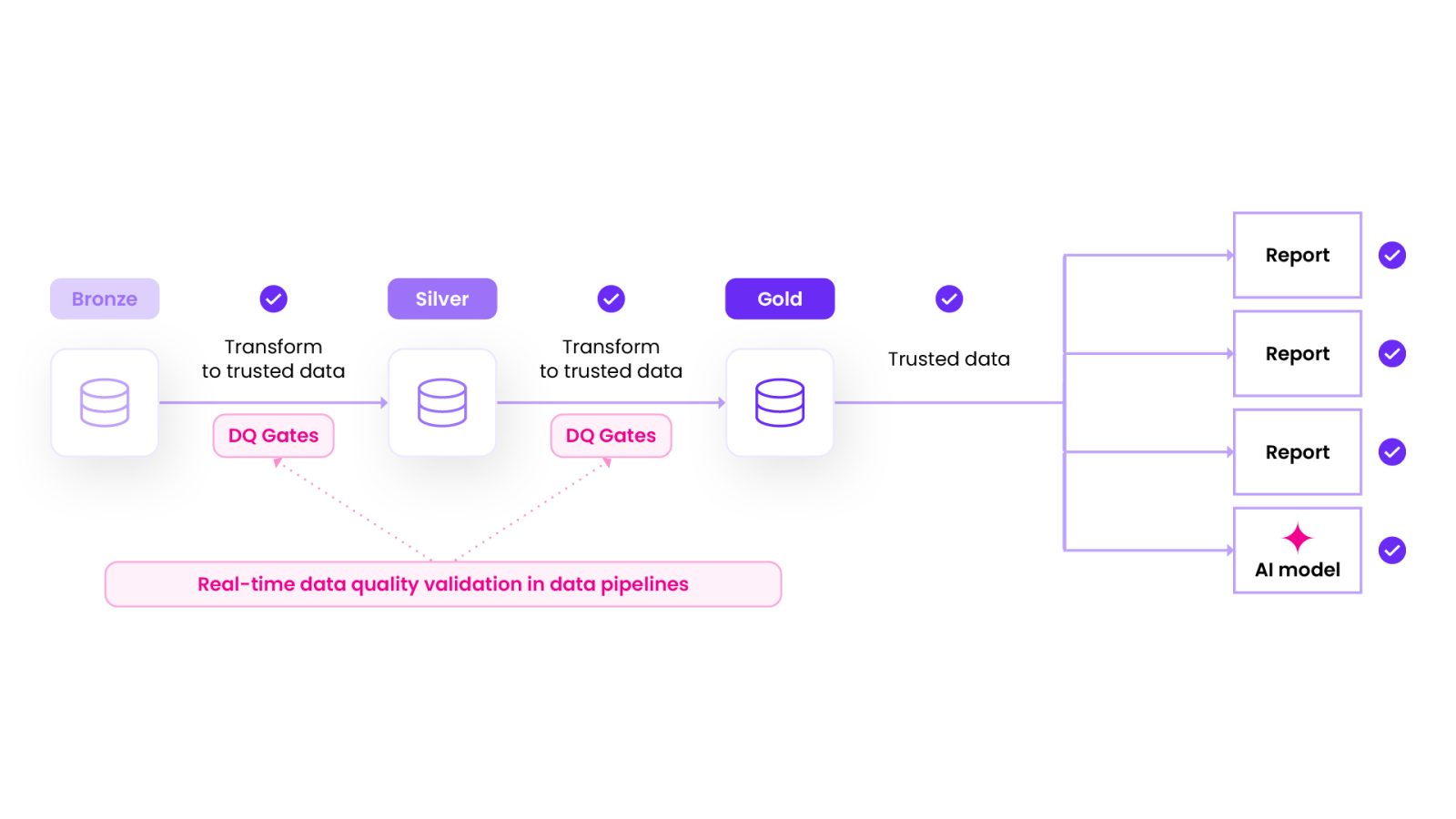
Giving engineers access to business rules
Traditionally, quality rules have been either buried in governance documentation or manually coded into pipelines. Both approaches create duplication and drift.
With Ataccama, business rules are defined centrally and exposed through Data Quality Gates. Engineers can apply them in pipelines without rewriting logic in SQL or Python. When a rule changes, such as a new compliance threshold, updates cascade automatically. No one has to touch the pipeline code.
How it works in practice
Ataccama takes a familiar principle – being, defined once, reused everywhere – and applies it to data quality. Rules are authored centrally in Ataccama ONE, right alongside catalog, lineage, and observability. That means governance and engineering teams are working from the same playbook, rather than duplicating checks in different tools.
From there, the rules can be applied in the environments where pipelines run: such as Snowflake and dbt. A lightweight Python library exposes governed rules inside pipelines, so engineers can pull them in as part of their normal workflow.
The checks themselves run natively. In Snowflake, they execute as SQL functions. In dbt, they integrate directly into transformations. Validation happens where the data lives, without detours to external systems.
What teams gain
For data engineers, this eliminates the constant rework that is one of the biggest time drains. Instead of writing ad hoc checks in SQL or Python, they can reuse governed rules that are already maintained by the business. Pipelines deliver data that is trustworthy by design, not by after-the-fact cleanup.
Governance leaders get something equally valuable, which is consistency. Audit trails are clearer, and SLA breaches are less frequent because policies are enforced directly in the flow of data.
For CDOs, it creates confidence. Analytics and AI run on data that can be trusted. Costs tied to remediation fall, regulatory exposure narrows, and decision-making is built on a solid foundation.
Data Quality Gates extend Ataccama’s data quality suite into the pipeline itself. They make data quality the engine of trust for analytics, AI, and compliance, not an afterthought. By moving validation upstream, organizations prevent errors before they spread and deliver trusted data everywhere it is needed.
Read the full press release and watch the demo to see Data Quality Gates in action.
Lauren Ruth
Lauren is the Director of Global Communications at Ataccama. With over a decade in the data industry, she specializes in strategic communications and has helped fast-growth startups define and amplify their data stories. She previously led communications at Alation and Informa Markets and holds a dual B.S. in Business and Communication, with a specialization in Technology, from Cornell University.