Webinar
How AI is Transforming Data Management
August 13, 2019
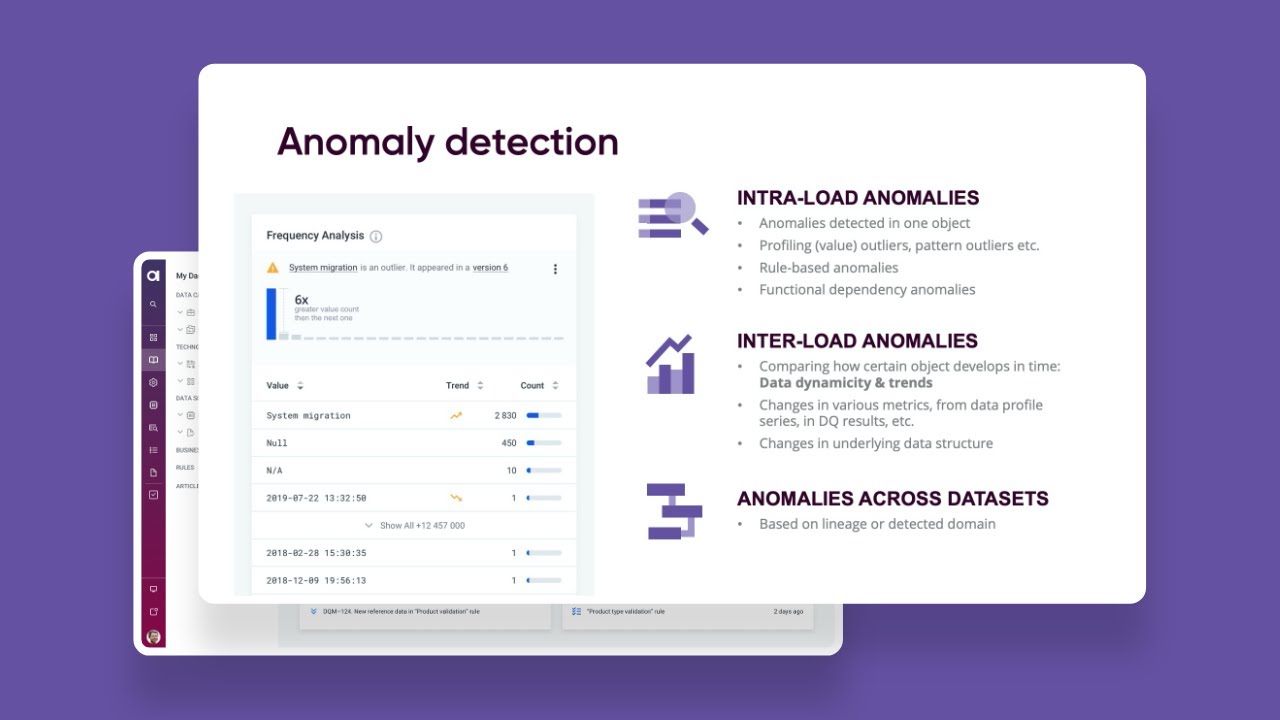
Finding valuable insights in your data is not simply a matter of having vast quantities of it available, but of being able to find the right data when you need it. From business term suggestion, relationship discovery, and anomaly detection to data quality and MDM optimization, the use of AI in data management helps stem the tide of data chaos and ensures that your data is orderly, correct, and easy to find.