The Rise of the Data Trust Layer in the Modern AI Stack
For the last decade, the modern data stack focused on a single goal: helping organizations understand their business. Companies spent millions consolidating data into storage powerhouses under the assumption that visibility equaled readiness. This architecture functioned primarily because humans were part of the system. When an analyst saw a duplicate or a formatting error on a chart, they mentally corrected it before taking action. In short, humans acted as the safety buffer between messy data and business decisions.
However, the transition to agentic AI has effectively removed that buffer. Today, enterprises are building for autonomous agents that do not just read data, but act on it. These systems lack the human intuition to pause when they encounter an anomaly or debate a conflicting definition across teams. Consequently, information that was once “mostly accurate” for a dashboard becomes a massive liability when it drives real outcomes. If an agent is fed bad data, it will not just produce a confusing report; it will process the wrong refund, email the wrong customer, or trigger a compliance breach at machine speed.
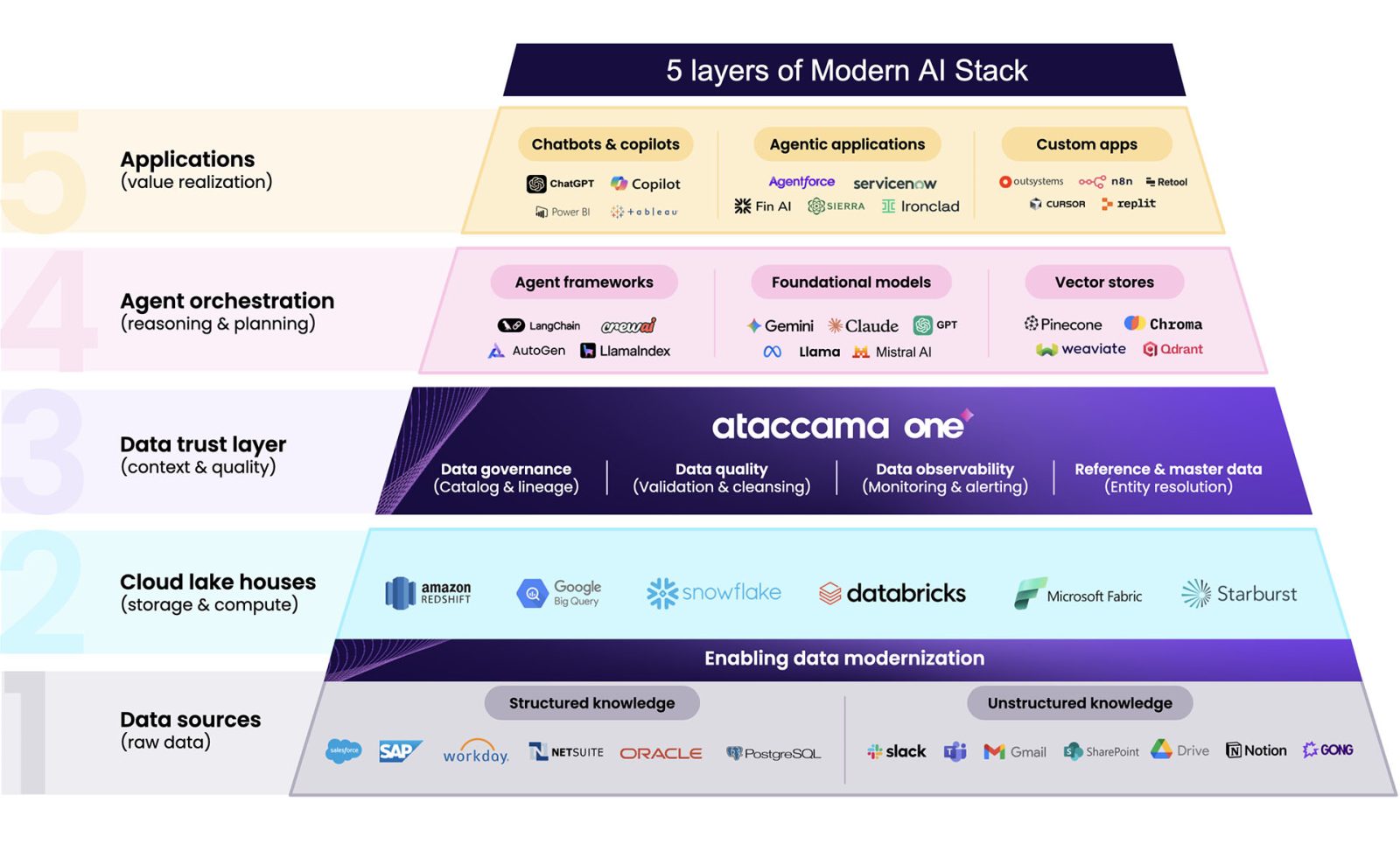
Five layers of the Modern AI Stack
Why the AI Data Cloud Needs a Brain
To meet this challenge, organizations are leaning into the power of the AI Data Cloud. Platforms like Snowflake and Databricks provide a world-class engine for storage and compute. They successfully solve the problem of scale and provide technical catalogs to track where data lives. However, for an AI agent to move from “reading” to “acting,” it requires more than just high-performance storage; it needs business context.
While a data cloud is designed to make information accessible, it is not its role to determine if that data is actually fit for the specific business decision an agent is about to make. This “trust gap” is where many AI initiatives stall because data clouds store bad data just as efficiently as good data. To resolve this, organizations need a dedicated trust layer that sits between storage and execution. It acts as the “pre-frontal cortex” for AI infrastructure, validating and governing the data before an agent ever touches it. Put simply, this layer helps enterprises fix bad data and ensure they are only using trusted, high-quality data for AI.
Why Data Trust Cannot Be “Ruleless” Alone
Implementing this layer requires a shift in how we think about quality. There is a narrative that “ruleless” anomaly detection is a complete substitute for data quality. While these techniques are helpful for catching technical blips and pipeline signals, anomaly detection alone is not the same thing as enterprise trust. Detection identifies that something is different, but it cannot understand intent. It cannot tell you whether a change is harmful to a specific business process or if it violates a strict policy.
In a complex enterprise, “good data” is not a statistical average; it is a deterministic requirement. A consent field must be correct, a product hierarchy must follow policy, and a risk flag must be explainable under audit. Relying solely on ruleless signals can create a state of false confidence, where a team sees no anomalies yet still has data that is unfit for use.
Ataccama bridges this gap by combining detection with agentic enforcement. We use AI to help generate data quality rules quickly, while still grounding trust in the deterministic requirements the business depends on. We believe the future isn’t a choice between rules and AI, but a hybrid model that uses each where it is strongest: observability for pipeline integrity and agentic automation for business intent.
The Competitive Edge of Responsibility
The modern data stack helped organizations understand their business. The modern AI stack must help them run it responsibly. This shift is required in regulated environments, where accountability is non-negotiable and explanations matter as much as outcomes. In sectors like financial services, every automated action must be explainable and defensible under audit. Organizations cannot simply tell a regulator that “the model did not flag an anomaly” and expect to pass.
To operate safely, AI needs deterministic context. Ataccama provides that foundation by removing ambiguity before data reaches the agent. As a result, enterprises can move from risky experimentation to scalable automation, because they can trust what the agent is using, explain what it did, and defend why it did it. It is time to stop treating trust as a manual workflow or a passive dashboard. Instead, it must become the architectural foundation for the enterprise.
Build your AI on a foundation of certainty, not anomalies.The modern AI stack is only as powerful as the data that fuels it. If you are ready to move past passive observation and implement the critical trust layer your agents require to execute safely, we can help – book a demo today.
Jay Limburn
Jay Limburn is Chief Product Officer at Ataccama, where he leads a global team of product managers building a market-leading data quality and data trust platform that helps organizations trust their data. Jay brings deep expertise across data quality, governance, and AI, helping customers reduce compliance risk and improve transparency with capabilities like observability, lineage, and automated remediation, so teams can move faster with analytics and deploy AI with confidence.