


Agentic data quality
for the AI era
Complete data quality workflows up to 9x faster with the ONE AI Agent, your digital
data steward, and deliver trusted, AI-ready data at scale. The data trust layer
regulated enterprises need to move confidently into the agentic era.
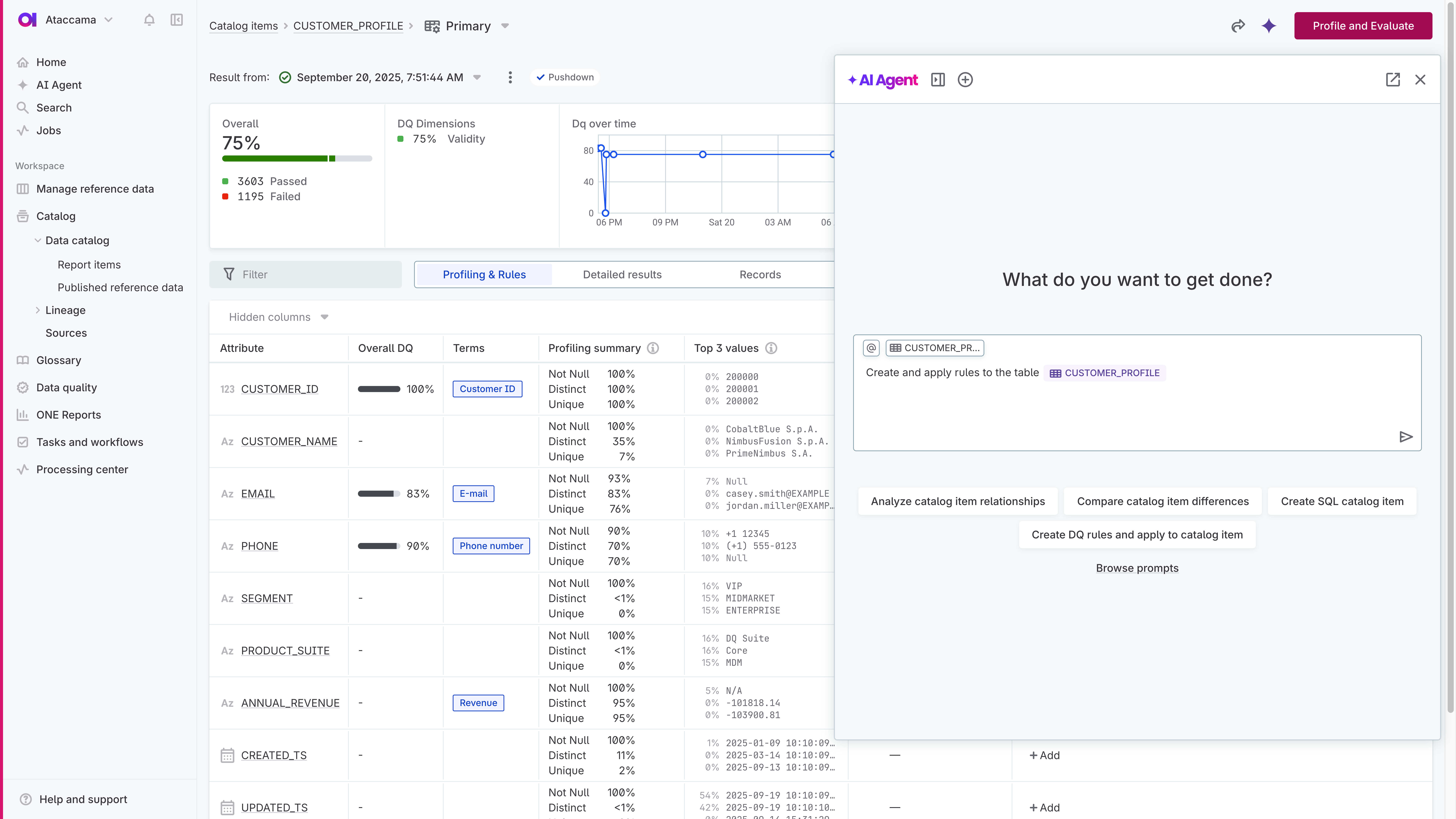
Agentic data quality management
Ataccama ONE introduces the AI Agent, your co-worker for data quality. Write a prompt, and it plans and executes entire workflows autonomously in minutes.



Drive business outcomes with trusted data


Mitigate regulatory and security risks
Achieve complete, audit-ready trusted enterprise data to mitigate penalty risks. Ensure compliance with key industry regulations such as Basel, Solvency, and the Dodd-Frank Act.

Make your data AI-ready
Go beyond basic data checks. Actively improve data quality. If you can't trust your data, you can't trust your AI. Trusted, high-quality data fuels accurate agents, models, and business decisions.

Reduce costs and improve efficiency
The old way (manual fixes, reactive teams, repetitive work) doesn't scale. The ONE AI Agent automates end to end, increasing data team efficiency by up to 50% while streamlining your tech stack.

Improve customer lifetime value
Deliver clean, trusted customer data for campaigns, reports, and apps that drive personalized experiences. Keep customers engaged, satisfied, and coming back.

Grow market share & drive revenue
Move faster with accurate, clean, reliable data. Improve forecasting, refine pricing strategies, and accelerate product innovation to increase revenue.

Maximize efficiency with Agentic AI
Our customers save on average
83% of their time with
agentic automation.
Agentic AI cuts the time to create
and apply a single data quality
rule from 9 minutes to 1.
Automating 1,500 rules per
year translates to 25 workdays
saved thanks to Agentic AI.
End-to-end data quality management
for trusted enterprise data
Unlike tools that only observe issues, Ataccama is the only platform that manages
data quality end to end, finding problems and acting to fix them autonomously. Your
data stays trusted, reliable, and AI-ready.
Explore and understand your data
Get clear insights from day one, right out of the box. Understand your data at enterprise scale with automated profiling, alerts, and lineage.
-
Data catalog
Every data asset is easy to find in the data catalog, clearly marked with quality and data trust scores, profiling results, and other insights you can rely on.
-
Data profiling
Our data quality platform profiles datasets, detecting patterns and distributions to help you spot issues and create precise data quality rules.
-
Augmented data lineage
Explore lineage with built-in data quality insights and business context to understand your data from source to consumption. Assess the impact of changes, identify root causes, and resolve issues faster.
-
Data Trust Index
Understand the trust level of your datasets with the Data Trust Index. This real-time signal tells both humans and AI models whether a dataset is reliable, accelerating your data through the medallion architecture and helping you identify which datasets are ready for production use.
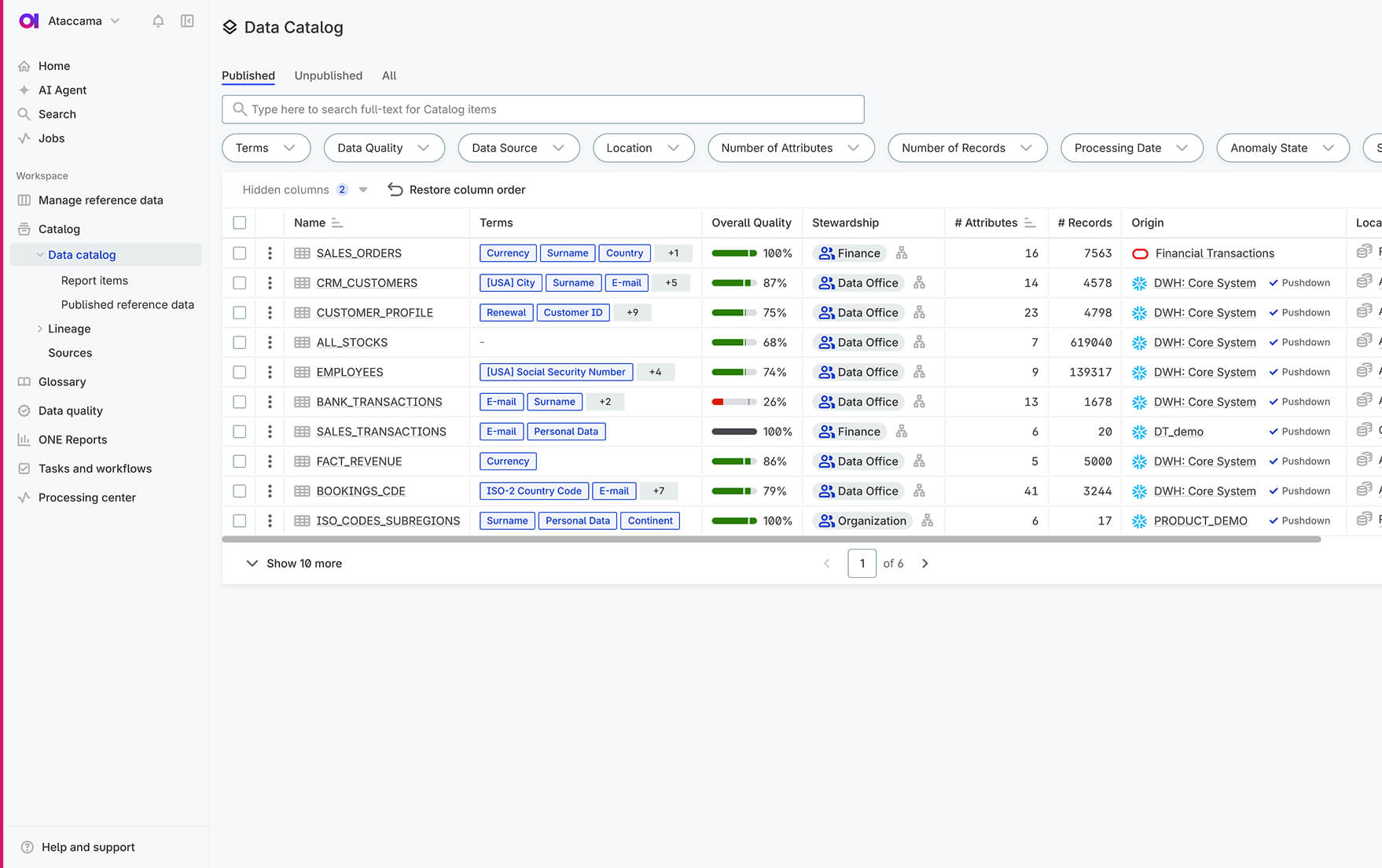
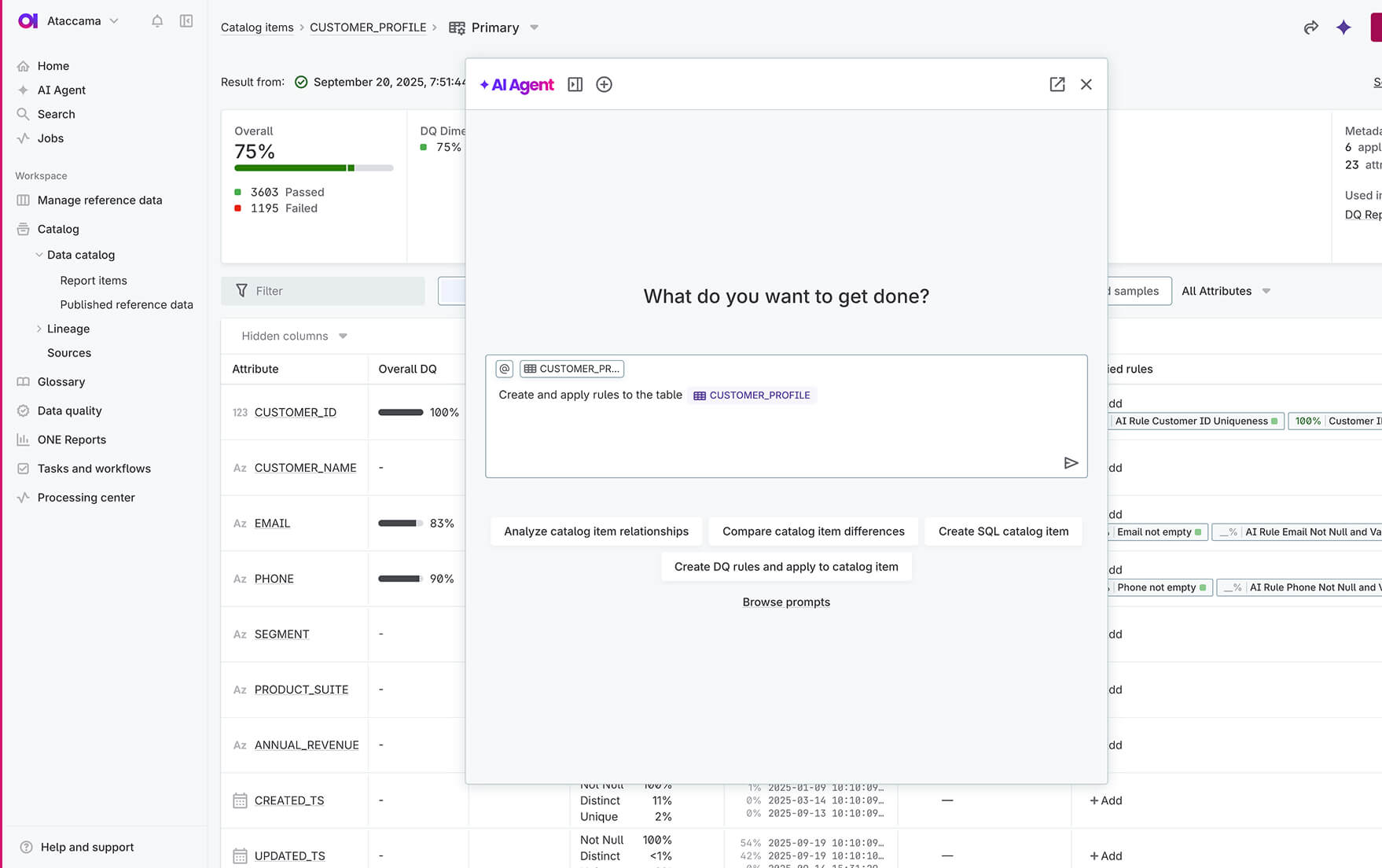
Define and monitor
enterprise data quality
Setting up your data quality management is easier and faster than ever with Agentic AI. Automate everything from rule creation to monitoring, and stay ahead of data quality issues with instant alerts and insights.
-
AI-powered rule creation
Set a goal, and the ONE AI Agent, your digital data steward, handles work end to end, accelerating bulk tasks like rule creation and applying them across dozens of datasets fast. Build complex rules using reference data or external APIs. This is data management in the agentic era: faster rule creation, consistent governance, and easier scaling across datasets.
-
Central rule library
Ataccama ONE acts as the single source of truth for governed, business-defined rules, enabling consistent reuse across your data landscape. It detects similar rules, prevents duplicates, and streamlines versioning and approvals.
-
Data quality monitoring & reporting
Monitor data quality automatically and catch issues early. View reports directly in the platform or integrate data quality metrics into Tableau or Power BI via API for tailored enterprise analytics.
Improve quality
Once you’ve assessed data quality and identified issues, automate remediation with no-code transformation plans that cleanse and standardize data at scale. Deliver clean data that’s ready for reporting, analytics, and AI.
-
Automated standardization & cleansing
Standardize values, like country codes, phone numbers, and SKUs, and fix common cleansing issues.
-
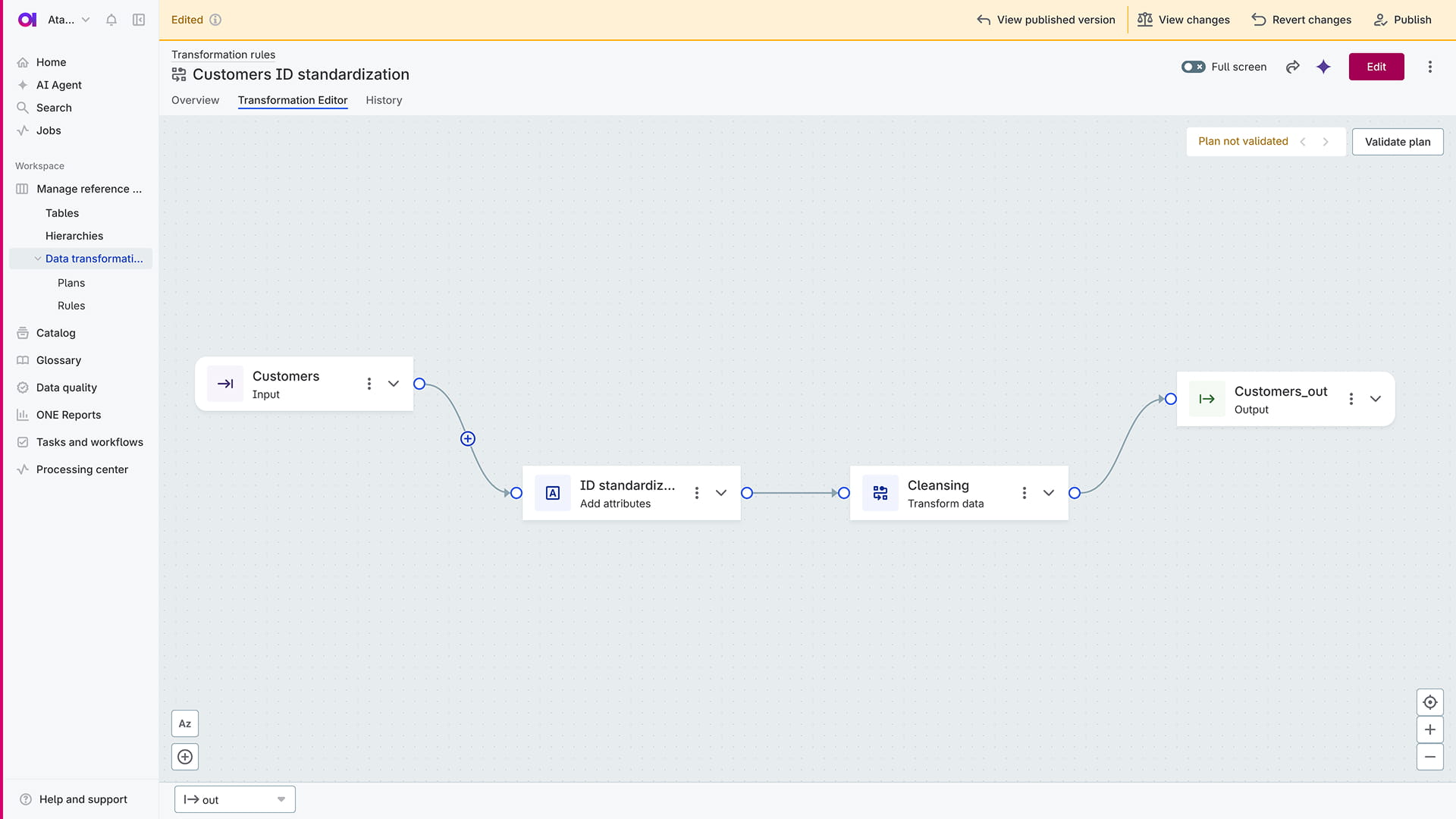
AI-assisted transformation plans
Create transformation plans across multiple data sources using natural language and a visual editor. Build reusable workflows, preview and debug transformations with AI assistance, and publish improved, trusted data.
-
Data remediation
Ataccama automatically identifies and delivers a clear list of data issues. Users can analyze, prioritize, and share issues with data providers or owners, driving faster resolution and continuous improvement in data quality.
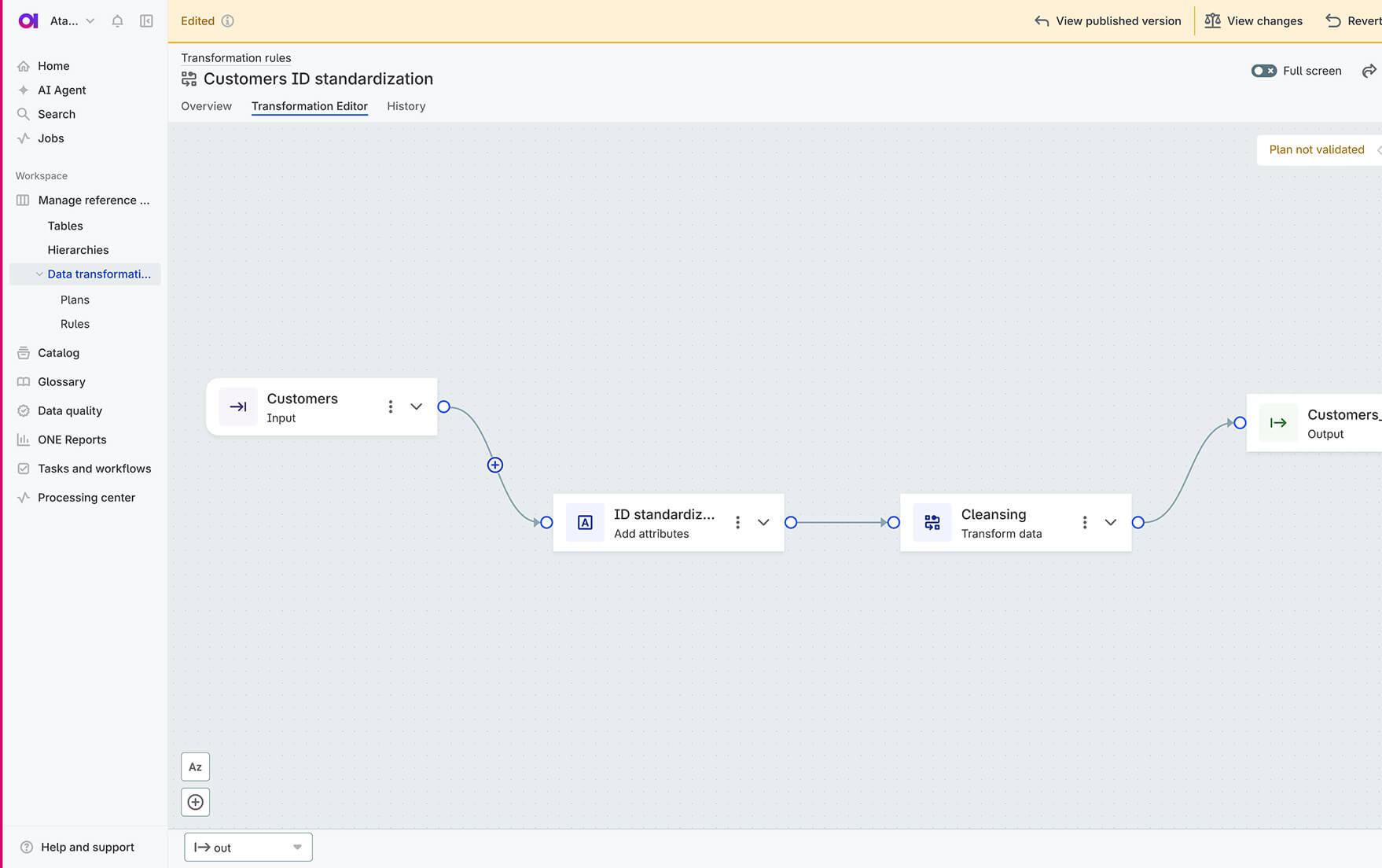
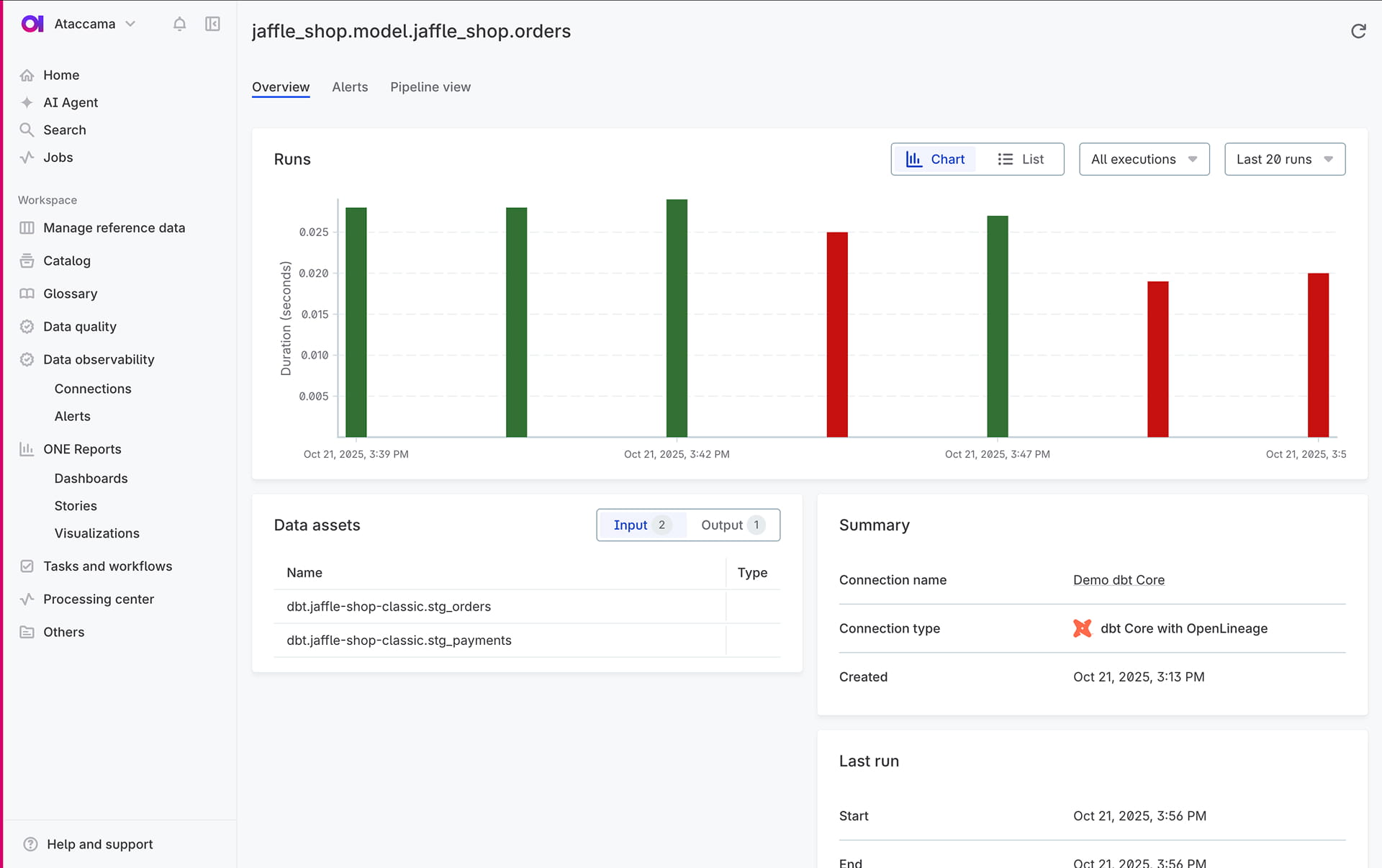
Prevent data quality issues before they spread
Define rules once and apply them everywhere. Ataccama ONE empowers business and governance teams to create data quality rules that data engineers can apply directly in apps and pipelines to catch bad data early.
-
Incorrect data entry prevention
Validate data at the point of entry using REST or GraphQL APIs to ensure only data that meets defined requirements enters your systems.
-
Embedded rules in data pipelines
Embed data quality checks directly into pipelines, validating data natively. Expose business rules as native Snowflake functions for integration with dbt.
-
Pipeline observability
Detect pipeline failures upstream of critical data assets. Catch potential issues early, before they affect your business.
The leading data quality solution built for
scale, speed and data trust
Built for enterprises evaluating AI-based data quality tools,
Ataccama helps you automate rule creation, monitoring, and rexmediation end-to-end.
AI-powered automation
Use the ONE AI Agent, your digital data steward, to create, test, and deploy data quality rules. Designed for scale, it runs end-to-end workflows autonomously, freeing your team for strategy.

End-to-end data quality management
Go beyond data quality monitoring with automated validation, cleansing, and remediation to actively improve and maintain trusted data across all critical data elements.

Reusable rules for all your systems
Create data quality rules once and reuse them at enterprise scale across multi-cloud or hybrid environments, systems and pipelines. Ensure high performance and security with edge or pushdown processing.

Part of the unified platform
Ataccama ONE unifies data quality, observability, lineage, cataloging, and reference data in one natively built platform. Your data trust layer, not a suite bolted together through acquisitions.



Experience
the Ataccama difference
Stronger data initiatives
with improved business outcomes
management
in the first 3 years
Estimate the potential ROI of Ataccama with our calculator.
Prove the value of your data in minutes.
Data quality software trusted by users and
analysts alike
-


One solution with one interface for 3 interoperable modules for reference data management, master data manatement and for data quality.
 John Reimers Master data program manager, Marti Group
John Reimers Master data program manager, Marti Group -

With Snowflake and Ataccama, Judo Bank can deliver cleaner data faster, with improved visibility into data quality and usage.
 Thomas Janssen Head of Data Architecture & Governance, Judo Bank
Thomas Janssen Head of Data Architecture & Governance, Judo Bank -

If we can’t trust our customer data, we are not able to do any growth initiatives and communicate effectively with our clients.
 Chantale Boulanger Director, Industrial Alliance
Chantale Boulanger Director, Industrial Alliance -

Bringing business and IT teams together to create a digital factory of trusted data.
 Piotr Pietrzyk Head of Data Governance, Avon
Piotr Pietrzyk Head of Data Governance, Avon -

Scaling data management initiatives across the organization, unlocking further growth and innovation.
 Michelle Sklar IT Governance Principal, Fifth Third Bank
Michelle Sklar IT Governance Principal, Fifth Third Bank



{kind=link}
Discover practical use cases
See how Ataccama ONE Data Quality can address your specific business needs.
Tailored for your industry
Learn how businesses in your industry are leveraging Ataccama for success.
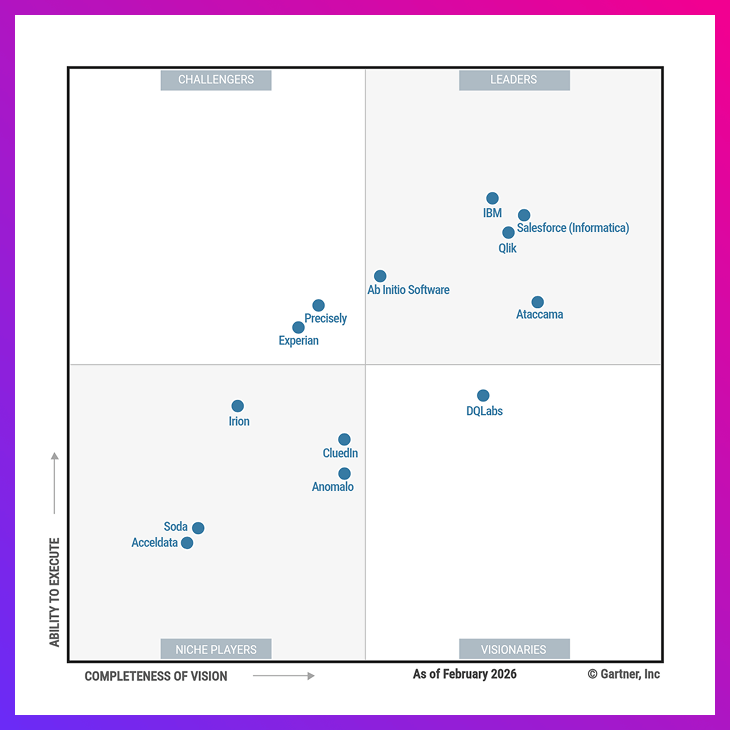
5-time Leader, with the furthest vision
Ataccama positioned as a Leader in the 2026 Gartner® Magic Quadrant™
for Augmented Data Quality Solutions for 5th consecutive time.
FAQ
A data quality platform is software that assesses, monitors, and improves enterprise data throughout its lifecycle. It maintains accuracy, consistency, and compliance by automating tasks such as profiling, validation, cleansing, and anomaly detection.
Ataccama’s data quality suite uses Agentic AI to automate validation, monitoring, and remediation workflows end to end. This reduces manual effort, speeds up rule creation and deployment, and provides trusted data for reporting, analytics, and regulatory compliance.
AI-based data quality tools (also called AI data quality tools or data quality tools with AI) use machine learning to detect anomalies, recommend or generate rules, and uncover patterns that traditional rule-based checks can miss. They adapt to changing data conditions so organizations can prevent issues and maintain trusted data at scale.
Many organizations see measurable improvements within weeks. Out-of-the-box profiling, validation, and remediation workflows accelerate adoption, while Agentic AI reduces the time required to create, apply, and manage data quality rules at scale.
Yes. The platform supports regulations such as Basel, Solvency, and the Dodd-Frank Act by providing audit-ready controls, lineage, validation, and reporting to demonstrate governance over sensitive data and reduce compliance risk.
Industries with strict compliance requirements and high data volumes benefit most. Financial services, healthcare, retail, manufacturing, and public sector organizations use data quality tools to improve accuracy and support better decision-making.