Maintaining data quality is essential for any business that values its data. It can lead to time savings for your data users, ensure the data you're working with is accurate, and benefit decision-making by improving the accuracy of your analytics.
If you store your data on Snowflake, you benefit from its ease of use, speed, and scalability. Because Snowflake is so central to many organizations, end users often expect that data quality is guaranteed.
Unfortunately, that's not always the case. Snowflake presents many options and opportunities for you and your data, but it also brings some pitfalls and challenges to maintaining data quality. This article will discuss those challenges and how to address them. But first, let's look at why people are using Snowflake.
Why use Snowflake?
Snowflake is a cloud data platform where companies can store, process, and analyze large volumes of data on a subscription basis. It works with structured and unstructured data, allowing users to create data warehouses and lakes.
Some of the benefits and reasons businesses choose Snowflake include:
- It can load and ingest data from a wide range of sources. Snowflake can work with structured and unstructured data, flat files, and real-time streams.
- Built-in data exchange and sharing features. Snowflake users can share and exchange data with other companies or individuals who also use Snowflake.
- Works with massive volumes of data. Snowflake can handle petabyte-scale datasets.
- Pay-as-you-go. In Snowflake, you pay for two things: storage (volume of data) and per query (the number of jobs/functions you run on your data). This way, you only pay for what you need with no additional expenses.
- Very flexible and scalable. Everything on Snowflake happens in the cloud, so your company doesn't need to manage hardware or adjust systems as you grow. No need to improve or upgrade infrastructure. Just expand your plan with Snowflake and pay for more extensive services.
- Rapid data exploration. As with anywhere you store your data, you'll need tools that help you quickly understand it. Snowsight from snowflake supports quick data exploration with features such as autocomplete, automatic data profiling, visualizations, dashboards, and collaboration.
Your Snowflake data deserves some data quality love
End users, such as data engineers, scientists, and analysts, love using Snowflake for four main reasons:
- Straight-forward data ingestion.
- Accessible data sharing features, whether you’re sharing data internally or externally.
- Good data search and exploration features.
- Fast query execution.
Besides that, users treat enterprise data on Snowflake as a critical source for lightweight BI and analytics. That is why paying close attention to data quality on Snowflake is even more critical because the risk of spreading poor data to vital systems is higher than on other platforms.
Because it is so easy to share and access enterprise data or acquire data from the Snowflake Data Marketplace, many users automatically expect that the data is of high quality.
This creates data governance risks.
Ungoverned data
Unless strict guardrails are put in place, Snowflake users can ingest a lot of data into the platform, which might result in
- Single-purpose data sets. For example, data scientists might be playing with data to build models.
-
- There is no way of knowing whether this data set could be useful to others.
-
- It can also increase storage costs.
- PII or other sensitive data being stored unknowingly. This can lead to expensive fines and security risks.
A single-purpose dataset occurs when you create a dataset on Snowflake for your own purpose/analysis without making it sharable or universally accessible. This limits their usefulness to only the person who created them and increases storage costs. It also hinders future maintenance of the database – especially with regulations in mind when your dataset contains sensitive data (e.g., personal information).
For example, you may create a dataset that doesn't update regularly, and when someone tries to use it a month later, all of the data is inaccurate or unrepresentative.
A great alternative to this is creating data products – a fully packaged dataset solution that is accessible and useful to all members of the organization. This way, everyone's work with data is always useful.
High data quality expectations
Snowflake is a go-to place for data for analytics and reporting, so people expect high data quality, but it doesn’t have to be. Just because it's easy to use/access data on Snowflake doesn't mean the data is usable or in a workable format.
The reality is, spotting errors and inconsistencies in massive data volumes is nearly impossible with the naked eye. You need to use data quality tools to determine whether your data is up to snuff. Otherwise, you won't be able to trust your data, regardless of the platform you use for storage.
When onboarding users to Snowflake, it's vital to mitigate these quality expectations with hardcore governance protocols so no one makes the mistake of using dirty data to power analytics and downstream systems.
Easy data sharing
Data sharing is one of Snowflake’s unique features, and users love it. However, just as it is easy to share valid, accurate data, it is as easy to share unvalidated and inaccurate data. You can also run into trouble if you're sharing sensitive or private personal data without following regulatory guidelines.
The challenges of ensuring data quality on Snowflake
Snowflake offers several built-in features that could help classify, secure, and check data:
- Object tagging.
- Data masking.
- Access management.
- Column-level security.
- Row-level security.
Snowflake even has a data quality framework.
However, most of these are manual and require a fair bit of SQL-like coding. Besides, these features would be most helpful in managing tables that have been part of the design process for data warehousing purposes. The unknown unknowns brought in by agile teams for rapid data analysis and prototyping (or a mistake in a data integration process) could slip through the cracks.
Creating DQ rules (e.g., as SQL procedures) in Snowflake is possible. Still, it can be tricky when it comes to collaboration, their creation and maintenance, or sharing their results in an understandable form – and it does require a certain level of technical expertise (programming skills). This is manual data quality all over again.
For example, Implementing an SQL function or composing a select that checks if an account balance is within an expected range is not that complicated. However, you may want to check the validity of a street name while allowing minor typos (or verify certain required patterns of product code structure). In that case, it can get more complicated to express it in SQL or might even require coding beyond SQL and utilizing Snowpark to get to the functionality you need.
How to automate data governance and data quality assurance on Snowflake
To effectively maintain data quality on Snowflake in an automated way, you'll need some help. Dedicated data quality applications can deliver information about your data's quality in real-time. Specifically, you will need three tools:
Data catalog. The data catalog will help you organize, classify, and categorize data. Even if you use it just for Snowflake, you will have a great overview of what kind of data you store by department and sensitivity. It will also provide quick data quality insights through data profiling and keep track of the results from your DQ tools.
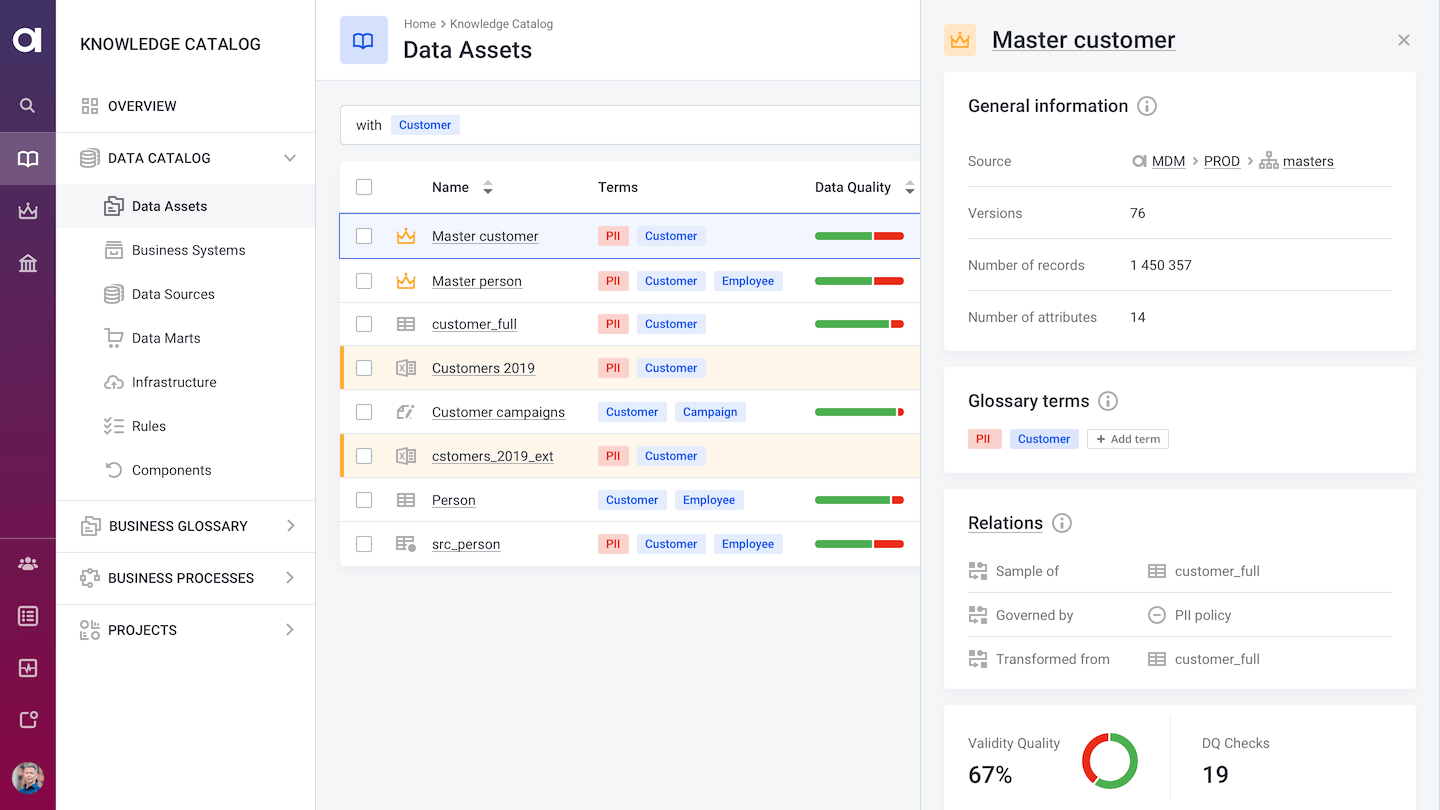
Some of the benefits of using a data catalog instead of using only Snowflake directly include the following:
- Better collaboration. Provides users with a friendly interface to access the data that interests them in full context. This includes automatically created insights into data sources (highlighting the most interesting characteristics), evaluated and clearly presented data quality and trends, and collaborative features like approval workflows, comments, and role-based permissions actions.
- Control over sensitive data. With an automated data catalog, you will always have PII and other sensitive data under control.
- Intuitive UI. It can be used by any user, from business stakeholders to data engineers.
- Automation. Automates data discovery and classification, and additionally, data quality insights.
Data observability and monitoring. Data observability is your ability to understand the health of your data landscape at any point in time and be alerted when an issue (even a potential one) is detected. On a dynamic system like Snowflake, the automated monitoring of your data via your own DQ rules and AI insights will detect the unknown unknowns. You will be able to react quickly, notify relevant stakeholders, and resolve data issues faster. Ultimately, you will be able to ensure that Snowflake users consume reliable, validated data.
By writing these rules in a dedicated tool, you can create a user-friendly way of implementing use-case-specific DQ rules into Snowflake without needing to code them manually—and then reuse them on other platforms.
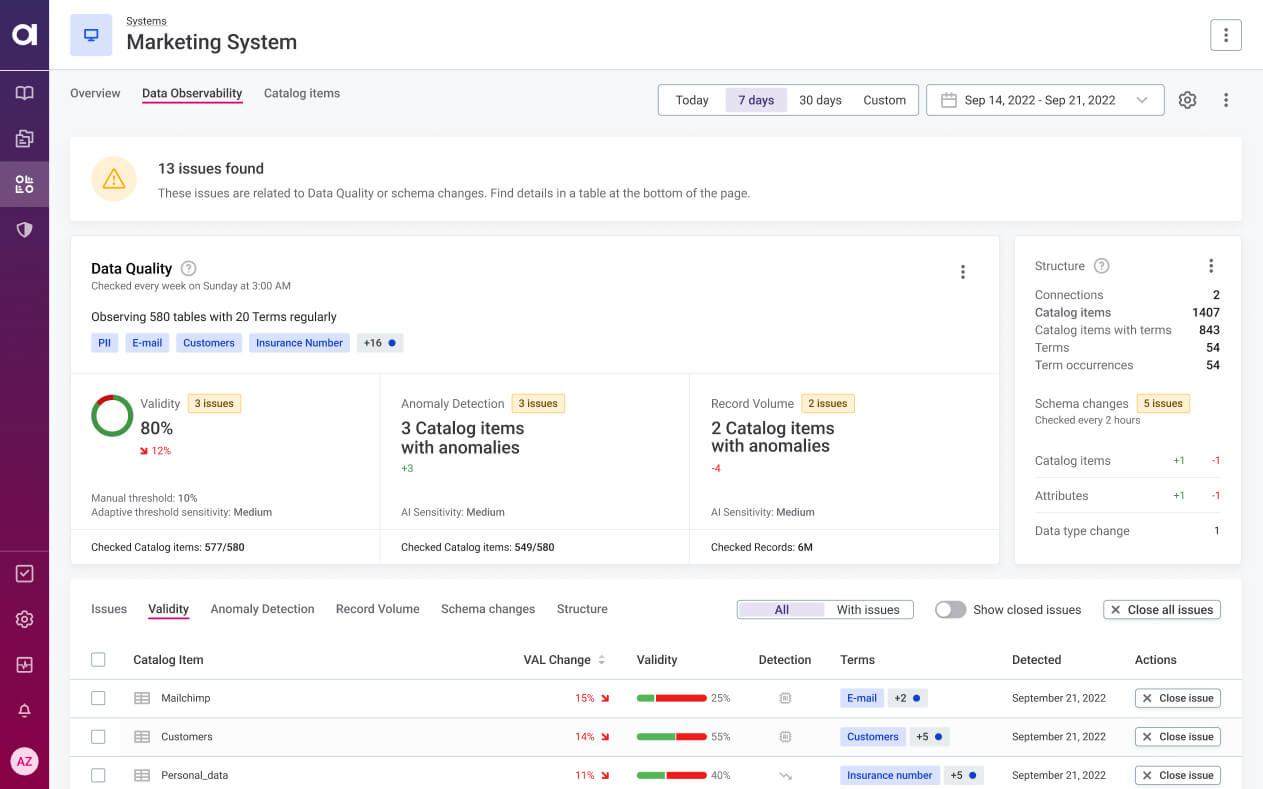
Data quality tools. Once you spot data quality issues via monitoring, you will need the means to fix and improve the data. This can be done through processes like data enrichment, cleansing, and transformation.
If you want to learn more about how these three tools work together, take a look at this article.
Address data quality on Snowflake with Ataccama
Data quality is not a given even on a great cloud platform like Snowflake. When data quality is not part of your data stack, you run the risk of unknowingly storing sensitive data on Snowflake and having users share unreliable data with each other and your business partners.
Ataccama partnered with Snowflake to ensure the most efficient and cost-effective data quality assurance for Snowflake users. Our new pushdown feature lets you evaluate and monitor data quality directly on Snowflake. Your data never leaves Snowflake, leading to faster processing speed, security, and efficiency!
If your organization relies on Snowflake for reporting and analytics, contact us to discuss your needs or learn more here.