
Covid-19 has disrupted life in unprecedented ways. Individuals and families have had to adapt to lockdowns, shelter-in-place orders, and other restrictions, while organizations across most sectors of the economy have either curtailed business activity or, in many cases, shut down altogether. Some of these organizations have started to rethink their business models and have launched or revitalized data analytics projects, seeking new revenue streams and a better understanding of their changing market and customer preferences. For governments, data and predictive models are now key to saving lives—perhaps for the first time in history. Data has never played a more important role than in the current crisis.
Unfortunately, the data around Covid-19 testing which is collected and used by governments in most countries—even highly developed ones—is unreliable. Reasons include poor data quality of individual data elements, as well as duplicate and inconsistent data collected for each tested person. This is the reason why most countries are only able to report a very basic statistic around testing: the number of tests conducted and the number of positive results. What is needed instead is a clear understanding of the number of new, unique individuals tested every day. This is one of the key metrics that needs to be factored into models, ratios, and ultimately in deciding the proper course of action around the pandemic.
The reason why most governments lack this statistic is because it requires eliminating data quality issues, integrating data from multiple collection points, and mastering it to merge duplicate data and obtain a single view of each tested person. None of this is possible without previously established data management and governance practices.
With modern data management technologies, governments would be able to use high quality, granular data to make the right decisions about the Covid-19 pandemic, such as imposing appropriate restrictions and reopening the economy at an optimal time and pace.
Problems with Covid-19 Data Collection, Processing, and Reporting
The following sections highlight reasons for the poor quality of Covid-19 testing data, challenges around integrating such data from multiple sources, and data issues arising from repeat testing of individuals.
Data Quality
Data from (and about) administered Covid-19 tests may come from hundreds or thousands of labs, hospitals, and makeshift collection stations. These institutions collect information about tested individuals to varying degrees of completeness and accuracy. They also have differing levels of digital maturity, with some recording patient information in free text form or old information entry systems, where input validation is rarely in place.
What’s more, health professionals frequently operate under tremendous stress while collecting data in suboptimal ways—by taking notes both on paper and electronically. It is also worth noting that collected samples are sent to labs where they are re-entered into lab information systems. All of these factors produce data that is frequently incomplete, invalid, and/or duplicated.
Repeat Testing
We have established that much of the data available to governments is of poor quality and therefore limited value. Governments are unable to determine the total number of people tested. Instead, the majority of countries measure the daily number of tests conducted, as opposed to the number of new people tested.
A key metric that countries therefore end up reporting is the number of newly infected people, divided by the number of tests performed on a given day. Unfortunately, anyone who has been tested more than once is included in this calculation, limiting the value of this statistic and its use in comparing test results among various countries.
Groups of people who are frequently tested on more than one occasion include:
- Those who have been hospitalized
- Those who have recovered from the virus
- Those who previously tested negative but still exhibit symptoms
- Hospital staff
Moreover, the day a test is conducted and the day the result becomes known are usually not the same, as it may take several days to obtain the result of a test. A fairer indicator of whether the pandemic is slowing down would be the ratio of newly tested people compared to new confirmed cases, presented as a weekly moving average.
Data Integration Challenges
Very often, data about a single tested person is captured, transferred, and stored in different systems, as swabs and blood tests taken at collection points are then re-entered in lab systems. Aggregating basic statistics, such as the number of administered tests or the number of new cases, is a matter of coordination, but even these statistics can be inaccurate because of human error.
By contrast, arriving at the number of unique people tested requires the integration of granular data across several data entities. Moreover, the more data is available and the higher its quality, the easier it is to detect correlations and understand causal relationships between data variables.
How Can Master Data Management Help?
To manage Covid-19 data effectively, it is necessary to bring together data from testing labs, cleanse and deduplicate data about tested persons, and create a golden record for each individual with accurate information about all of their tests. This means all data would need to reside in a central, consolidation-style MDM hub, and that the hub would receive new data on a regular basis from all sources, keeping golden records updated or creating new ones.
Consolidating data about individuals tested for Covid-19 would enable authorities to have a better understanding of the spread of the virus in their countries and regions. A central MDM hub with complete information would also serve as a reliable source of information for pandemic modeling, as our understanding of factors leading to the spread of coronavirus improves over the following months.
Enabling Smart Quarantine
It’s not only data about Covid-19 testing which can be mastered to aid in decisions around reopening the economy. Mastering phone numbers allows for the effective implementation of “smart quarantine,” or prompting individuals to get tested if they have been found to be in close contact with someone who tests positive. A centralized approach, powered by an MDM hub, enables the storage, tracking, and analysis of this information, reliably and on a per-person basis.
Address mastering can also be performed, resulting in a multi-domain MDM implementation. This entails collecting and integrating data from mobile phone operators and payment processing companies with the goal of detecting new disease hotspots, analyzing the movement of infections, and pinpointing the places of new infections. Such a solution could even work as an early warning system by using streaming technology and mastering location data in real time.
Other Benefits
| MDM Outcome | Benefits |
| Information about all tests a person has taken, including test types and outcomes |
|
| Deduplicated party data | Report and use more relevant statistics, such as the unique number of people tested compared to new cases |
| Complete party data, including comorbid conditions | Keeping a database of all tested individuals (not only confirmed cases but also negative test results) can help uncover dependencies and correlations over time. For example, smokers have recently been shown to be less likely to experience severe symptoms of COVID-19. |
Methodology and Solution Description
Data Acquisition, Processing, and Providing
This section describes how an Ataccama MDM solution can acquire, process, master, and provide COVID-19 data.
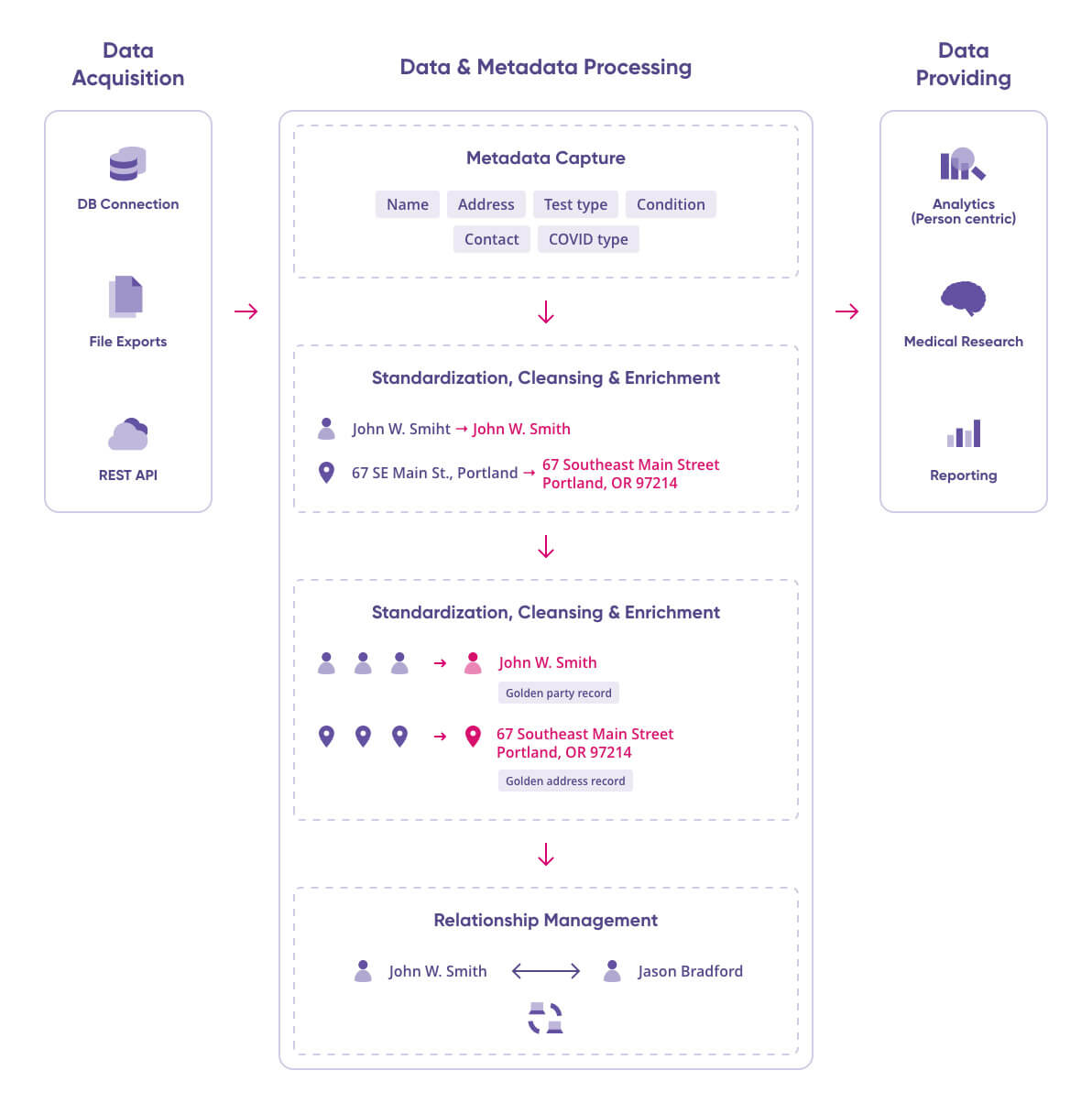
- Data acquisition: With thousands of labs, data integration patterns will be mixed. Some data will be provided as file exports, which will be collected by the solution and processed; another part of data will integrate via database connection or application connectors. If central collection, integration, and storage is already taking place for some groups of testing points, the solution can integrate data from these central data stores as well. Integration via APIs is also possible.
- Metadata capture: To integrate data (of varying quality) reliably, it is necessary to capture technical and, where possible, business metadata about sources, as well as basic data quality information about relevant data sets. This includes profiling data and obtaining statistics, such as value frequency, duplicate counts, value patterns (masks), and others, which help form an overview of the state of data in a given data set.
- Standardization and cleansing: The solution comes with a set of cleansing components for names, IDs, addresses, etc. Cleansing for other types of data can be configured based on business rules in place.
- Integration and mastering: Integration entails getting data from connected sources and bringing it to a common data model. Mastering entails deduplicating persons and mapping them to testing data in order to arrive at information on the number of tests each person has taken. The solution is able to integrate and master data incrementally from all sources regardless of their integration pattern.
- Relationship management: Collecting and storing contact information (specifically phone numbers) for tested individuals enables smart quarantining, as discussed above.
- Data providing: The Ataccama MDM hub is able to provide data in a variety of styles: batch exports, APIs, and streaming. The solution is also capable of online person identification, i.e., the ability to check if the person exists in the hub and prevent the creation of duplicate records.
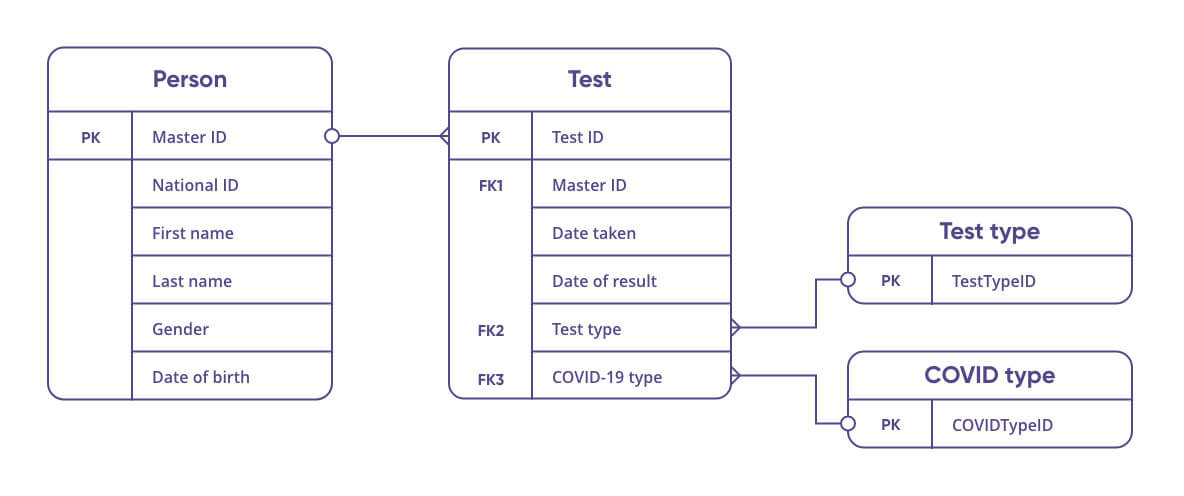
Suggested Logical Data Model
The following entities and relationships are suggested for the logical master data model. This model represents the final state of integrated, cleansed, and mastered data in the MDM hub, and can be extended with new entities if required in the future. The existing entities contain just a basic set of attributes for the purpose of this article (or example, the Gender attribute in the Person entity would have a reference data entity connected to it, but this is not shown here).
- Person: Standard information about the person who took the test, such as names, gender, date of birth.
- Test: Information about the sample, e.g., test type, test result, various additional attributes.
- Reference data entities:
- Test type: Test classification.
- COVID type: COVID classification based on the presence of symptoms, result of the test, etc.
The model can be extended with the following entities:
- Materials: Reference data on protective equipment, active ingredients, face masks, disinfectants, etc. These can be separate reference data entities.
- Sample collection point: Information about the place where the sample was taken.
- Address: A golden entity with address information for a multi-domain implementation, discussed above.
- Comorbid condition classification: A reference data table with comorbid conditions.
- Contact: An entity with deduplicated, up-to-date contact information, such as email and phone number, and which channel of communication is preferred.
Benefits for Governments and Businesses
There are still many unknowns about the Coronavirus: side effects, the degree of contagiousness, the chances of reinfection, treatment efficacy, and more.
A central data store with mastered data on Covid-19 testing and other associated data can help us contain the Coronavirus outbreak, help to manage similar pandemics in the future, and assist with the development of vaccines. However, this can only happen if the data used is of high quality and instantly available.
Aside from long-term research benefits, such master data can have short-term, practical benefits for businesses. As countries are starting to re-open their economies, many are still wary of a possible second wave of infection. To provide reassurance and bring an element of control to the situation, apps and services can be developed and used to prove one’s COVID-19 history. This might mean instant proof of a fresh negative test for someone who has never tested positive or proof of antibody presence for someone who has.
By having reliable master data instantly available to these third-party tools, businesses will be able to protect themselves better while “verified” individuals will be allowed to more fully support the economy.
Privacy Considerations
Of course, the above is possible only if people consent to having their medical and personal information collected, and trust that that information will be used only for legitimate purposes.
Ataccama software and solutions enable the automatic detection of sensitive information in all incoming data as well as its effective anonymization, ensuring compliance with GDPR, CCPA, and other privacy and personal data regulations.
Ataccama also provides the means for effective consent management. In the case of Covid-19, the solution can be granularly configured, determining which kinds of data can be shared, and who that data can be shared with. It is capable of processing updates to consents from source applications, as well as manual consent modification in the MDM hub.
The Bottom Line: We Can’t Do It With Poor Quality Data
Governments that have not established robust data management principles around Covid-19 are operating with unreliable data. There are several reasons for this:
- Data quality. Raw data is collected in conditions that result in mistakes and incomplete information, and cannot be trusted without proper cleansing and standardization.
- Repeat testing. Some groups of individuals are tested several times, which results in duplicate personal data.
- Data integration challenges. Covid-19 data is collected, transferred, and stored in various information systems across different institutions. It is extremely difficult to integrate this data fast and reliably without an established flexible data integration framework.
Because of these data problems, very few countries possess a key metric to understanding how the pandemic is progressing (at least in their country): the number of unique people tested (as opposed to the number of conducted tests).
Generating this metric is possible, however, with a modern data management platform such as Ataccama ONE, which delivers the following operations in an automated, iterable process:
- Acquiring data from multiple sources in a variety of integration styles
- Capturing technical and business metadata
- Standardizing and cleansing data based on the discovered metadata
- Integrating, mastering, and merging data about individuals and test results in a centralized MDM hub
- Determining and managing relationships between individuals
- Providing data in a variety of styles
Such a solution offers a number of benefits to governments and businesses alike, such as allowing for smart quarantine, more accurate analyses of the Coronavirus, and more informed decisions about reopening economies around the world.