When it comes to spotting low-quality data, there are two main approaches that organizations employ: rule-based data quality monitoring and AI/ML-driven anomaly detection.
Rules are a great way of injecting expert knowledge into your data system. However, that knowledge is only as good as the expert injecting it. Besides, rules require maintenance and resources to deploy to different systems.
AI, on the other hand, works autonomously and detects issues you wouldn't normally write rules for. But it may have some troubles of its own. It's only as good as the data you're feeding it, and it takes time for initial learning and fine-tuning.
That's why the best approach to spotting outliers and unwanted values in your data combines the two into a comprehensive web that catches all unwanted, low-quality data.
The best option is to have both
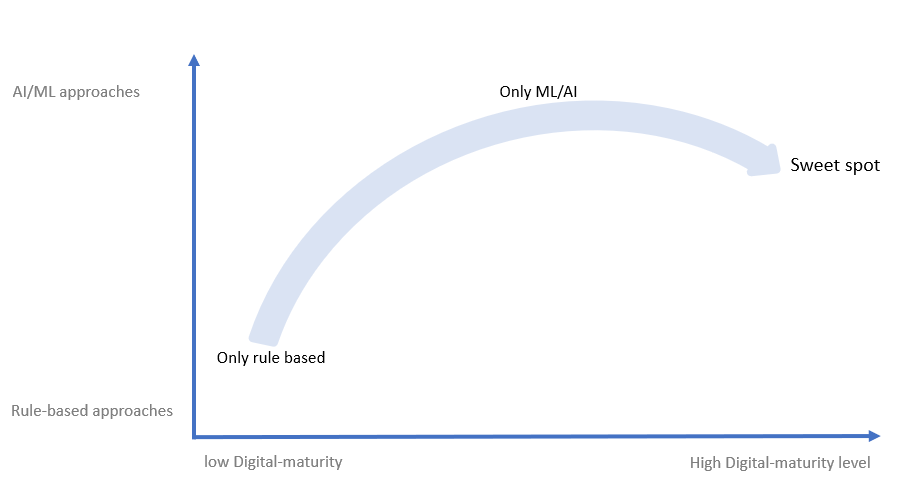
As businesses grow in their digital transformation, they recognize the importance of AI and machine learning technologies for data quality evaluations and anomaly detection. Those with low digital maturity choose only traditional approaches, primarily rule-based pathways. As they mature, they shift toward AI and ML models and heavily focus on them. However, optimal maturity occurs when companies recognize the need for a balance of both rule-based and AI/ML approaches – while still leaning more towards AI/ML because of their autonomous and adaptive nature.
For example, achieving great data observability (view a workflow here) requires a combination of the two.
Rule-based is still essential because it allows you to validate and transform data according to existing business requirements. This will cover use cases that are either too important or too specific to leave to the AI on its own. For example, validating data against a lookup of allowed or not allowed values, checking and standardizing formats of data for the data warehouse, or controlling the number of empty values in a specific column.
On the other hand, AI is effective in discovering real-time problems in data, finding complex relationships, and catching issues in data you wouldn’t expect or write rules for.
Combining rule-based and AI/ML methods is the best choice for ensuring high-quality data. Now, let's get into the specific advantages and disadvantages of each approach.
Rule-based approach
The most established method for checking/validating data is the rule-based approach.
This practice is foundational to data management. It was one of the first ways people checked for data quality.

Pros of the rule-based approach
Easily interpretable. It's easier to read and understand a ruleset (and why it flags data entries) than decisions made by AI.
Flexible/Editable. Rules can be manually removed, added, or changed. It's a lot more complex to change the inner workings of an AI algorithm.
External knowledge and compliance. When new regulations arise (such as those specified by the GDPR), you can immediately incorporate them into your rule library. This also applies to all explicit (external/internal) knowledge. It's much easier to inject it into your rules library than train your AI/ML to spot them independently. For example, a new regulation says that the tax in a low-income area cannot be more than 20%. You could then introduce the rule "Tax < 20%."
Cons of the rule-based approach
The rule-based approach has some evident shortcomings, mostly from its manual-intensive nature, requiring a lot of work on the side of experts and data stewards.
Heavy reliance on domain expertise. The rules are only as good as the expertise of the person writing them. They rely significantly on the expertise of domain experts, individuals who are intimately familiar with the data and have some expectations about how quality data should look.
This limits the number of people who can contribute to improving data quality. With the expansion of data fields and the emergence of data lakes, even an expert who understands the company (and the data) may not be able to define every single rule that could identify problematic entries in the future.
For example, suppose you want to make a rule for transaction limits (how much money you can send at one time) in the banking sector. In reality, not all customers should have the same limitations. You would have to answer various questions to create rules. Questions such as: how to extract the optimal limit per various customers? How to make sure that these limits change when the customer spends more time with the bank and their credits changes as well?
Rules require maintenance. While the Rule-based approach can be flexible, it demands manual activity (lots of energy and time) to change and maintain your rules library. Existing on their own, rule-based approaches are static and can only detect obvious irregularities. Such rules might have been defined in the past, based on older data, and therefore do not evolve and adapt and might be less relevant for new data.
For example, suppose you define a rule that a maximum transaction must be less than 100,000 (i.e., x < $100,000). However, after business growth and more high-profile accounts, clients regularly make that kind of transaction and are no longer viewed as outliers.
Creating and maintaining rules requires a lot of time and energy. Doing data discovery manually (column by column) can be incredibly slow. Also, the expert who writes the rules must be fully aware of all the company's policies and changes, so they must constantly read and update themselves to ensure the rules stay relevant.
This constant maintenance and inability to adapt to changing datasets lead to problems scaling the rule-based approach. Any failures in communication can lead to rules without justification or explanation: it's challenging to adjust these rules appropriately without explaining why they were set up in the first place. company policies.
Relationship discovery is harder. The rise of big data with various dimensions has made defining rules on individual data slices nearly impossible. Imagine you had a table with 200 columns. Defining rules that apply to all those columns would be almost impossible to do comprehensively (with so much variety, a single ruleset is obsolete). Alternatively, you could create individual rules for each of those slices, but this would also have some limitations. Consider the various relationships these columns have to one another – both those we are aware of and those we are not (maybe column x grows with y, but only if z is below a certain value). An AI could discover these relationships automatically while, if we create rules for them individually, we may ignore these relationships and miss a critical connection between the data.
For example, consider a detailed record of customer data. You may have columns for age, income, address, sex, etc. Maybe there is a connection between people living in a certain area, of a certain age, you can expect a certain income. Finding such a relationship among the columns would be complicated to do manually. You would have to profile each column, set up individual rules, and then notice this pattern on your own. An AI can discover these relationships automatically as soon as you feed it a dataset.
AI/ML anomaly detection
AI/ML methods address DQ by profiling datasets, finding patterns, and then using those patterns to find unexpected or "anomalous" values in new data. They address the disadvantages of rule-based data quality checks by enabling users to instantly automate the entire data quality control process and catch unknown and unexpected problems in their data.

Pros of AI/ML Anomaly Detection
Real-time insights/Adaptability. If the data changes in real-time, the AI will adapt simultaneously. While with rules, you would need first to recognize that this change happened (much easier to do with AI) and then adjust or write a new rule to address it.
For example, AI/ML models can adapt what they consider abnormal as your business grows. Let's say you have a bank that usually has 1,000 transactions per hour, and your AI recognizes anything over 5,000 as anomalous. The AI will continually update that number from 5 to 10 to 20,000, depending on the number of transactions your bank is conducting. You won't have to write a new rule every six months to account for your growth.
Little need for maintenance. Once the AI learns your system, it should be able to operate autonomously.
Can Identify unknown problems. As we mentioned in the disadvantages of the rule-based approach, AI can spot complex relationships between data (or columns in the data) that humans may miss. For example, it realizes that all your customers living in a certain area have an income lower than $100,000 yearly. It could then flag customers who reported living in that area but make significantly more.
Cons of AI/ML Anomaly Detection
These models can be complex to implement, taking time and effort to work effectively and completely understand your data. You'll need to try out different models; some will perform better than others. Even those that work well will require tuning, performance evaluation, and patience before becoming fully autonomous on your system. Here are some of the disadvantages of the AI approach.
Requires a lot of high-quality data. In one of our previous articles, we discussed the importance of data quality when building an AI. These models require large volumes of data to ensure they represent your system accurately. However, they only need such large volumes of data because most of it isn't very high quality. If you maintain high data quality standards, these models can require less data because these smaller, higher-quality chunks still represent your datasets as a whole.
If you're sensing a paradox, you're on the right track. How can you find high-quality data to build an AI that is meant to do exactly that – improve your data quality? The answer has two parts and depends on whether your AI is supervised or unsupervised.
- Supervised AI models: Supervised AI models need labeled data. A tag or label needs to indicate what something is (or isn't) for your use case. For anomaly detection, a supervised AI model would need labels to distinguish "normal" data points and "anomalous" data to learn which is which. Once it learns from these labels, it can automatically apply them to new datasets and find anomalous entities on its own. Of course, this relies heavily on having good labeling of your datasets.
- Unsupervised AI models: However, sometimes you don't have access to all that labeled data, and your AI needs to learn from your datasets independently. In anomaly detection, this use case requires you to make several assumptions about the dataset. The first and most important is that most of the entries in that set are "normal" while only some are "anomalous." This can be a disadvantage because, if this assumption is false, it can lead to a faulty AI. That's why it's better to use larger datasets because you have a better chance of most entities being "normal" and not "anomalous."
Explainability. One of the biggest disadvantages of AI is being a "black box." There is a lot of uncertainty in the business world that makes decision-making very difficult. Users need data models to reduce that uncertainty, not to add another ambiguity! Therefore, they expect AL/ML models to increase efficiency but be interpretable and explainable at the same time. Hence, one of the main challenges is how to develop AI/ML-enabled models that are comprehensive. However, many AI models will offer solutions or suggestions without any explanation of how they got there, making them harder to trust for business users who don't understand their inner workings.
Optimal performance takes time. While DQ rules are time-consuming because they can't change dynamically or adapt to the data, AI also takes a fair amount of time to set up and perform autonomously. After its implementation, you must monitor the AI carefully, see which model works best, provide input, and evaluate results for some time before the AI knows your system well enough to perform these tasks independently. You can implement a model that "works" almost immediately. However, for it to "work well" (with high accuracy), the AI needs time to learn about your data and will require fine-tuning on your end to ensure it doesn't miss any critical information (like new regulations or company policies).
Conclusion
We now see that the rule-based approach is easy to use and adjust but requires a lot of effort and manual labor. AI solutions can be the answer, but they also have drawbacks regarding their complexity and implementation.
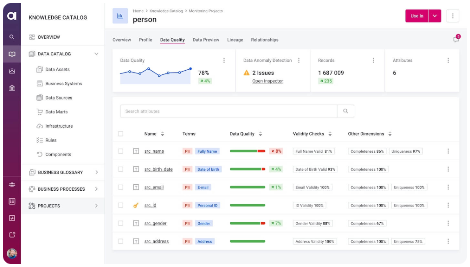
The best approach is to have both solutions married together. Ataccama believes in delivering both approaches and supporting organizations in finding their sweet spot based on maturity and digital evolution. That's why we've built a catalog with integrated data quality evaluation tools and anomaly detection, allowing you to flag anomalies using AI approaches and set up DQ rules all in the same place.
See rule-based and AI-powered DQ in action
Watch demo