Flexible Data Integration
Integrate data from a variety of sources, improve data quality, and deliver reliable to user in a variety of styles.
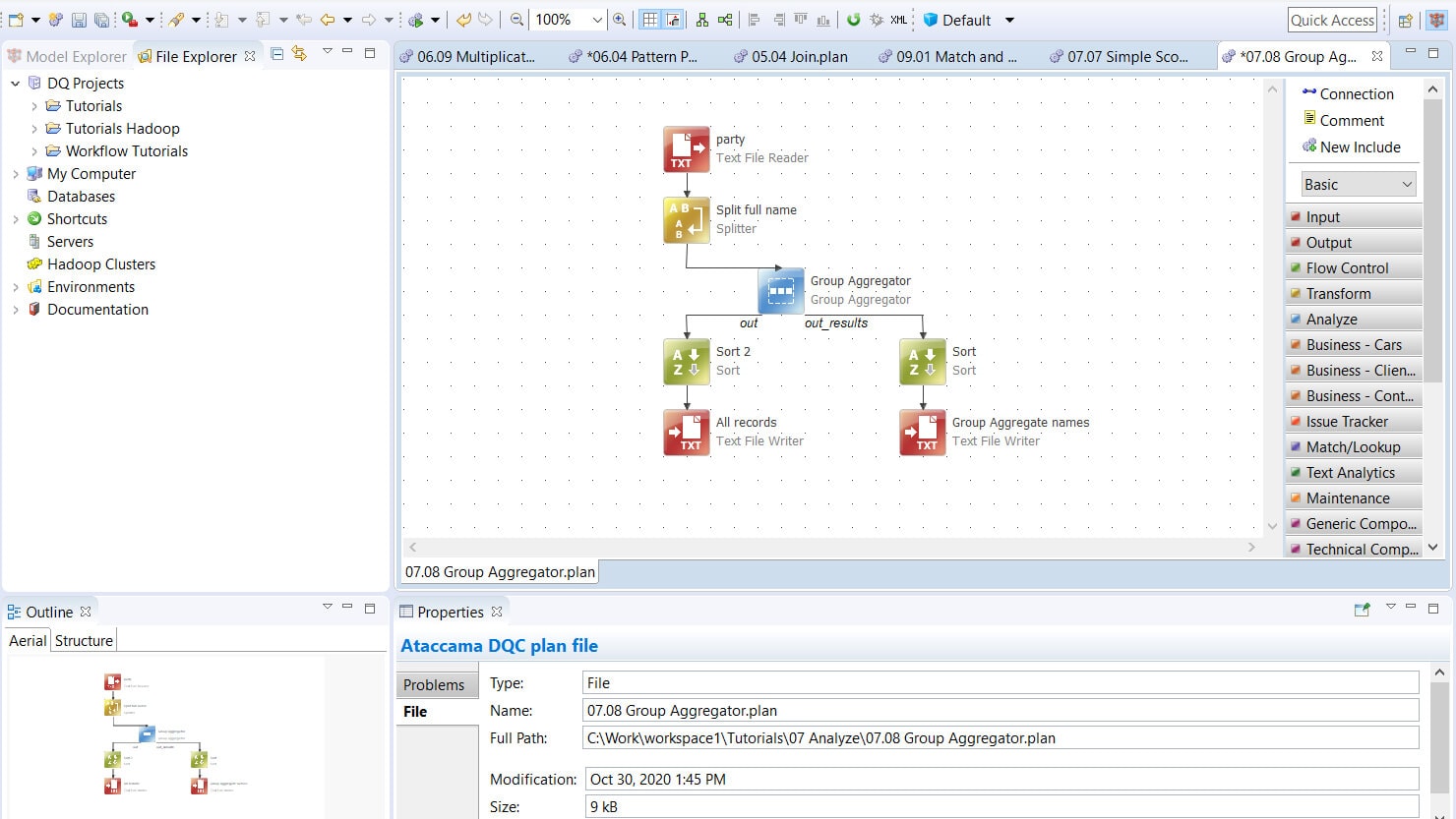
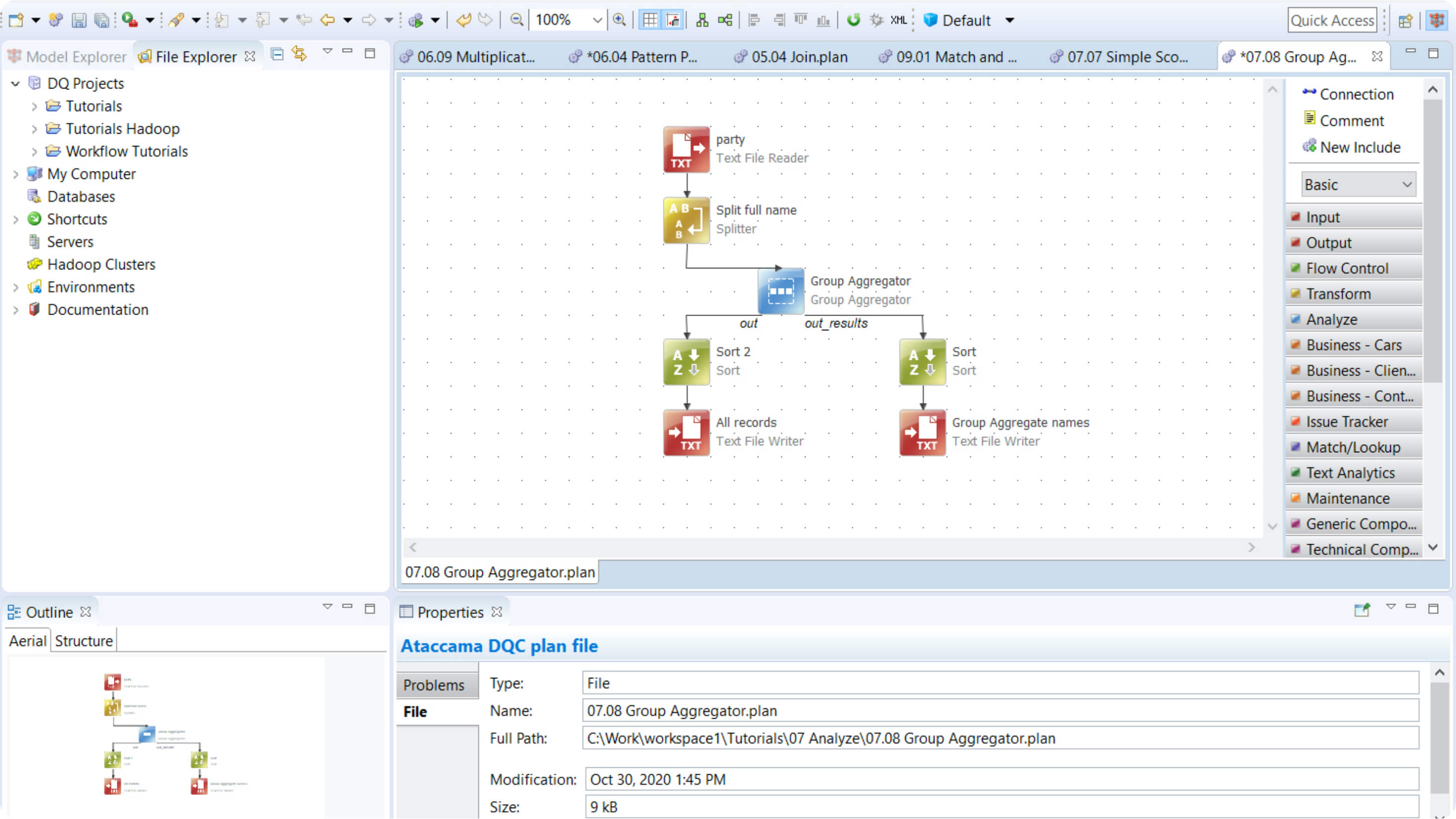
Easily create, test, and deploy data integration pipelines

Do it your way
Flexible ETL
Whether you need to implement a predefined data pipeline without seeing the data, interactively work with data, or transform data directly in the data lake, it’s all supported.
Save time preparing transformation pipelines
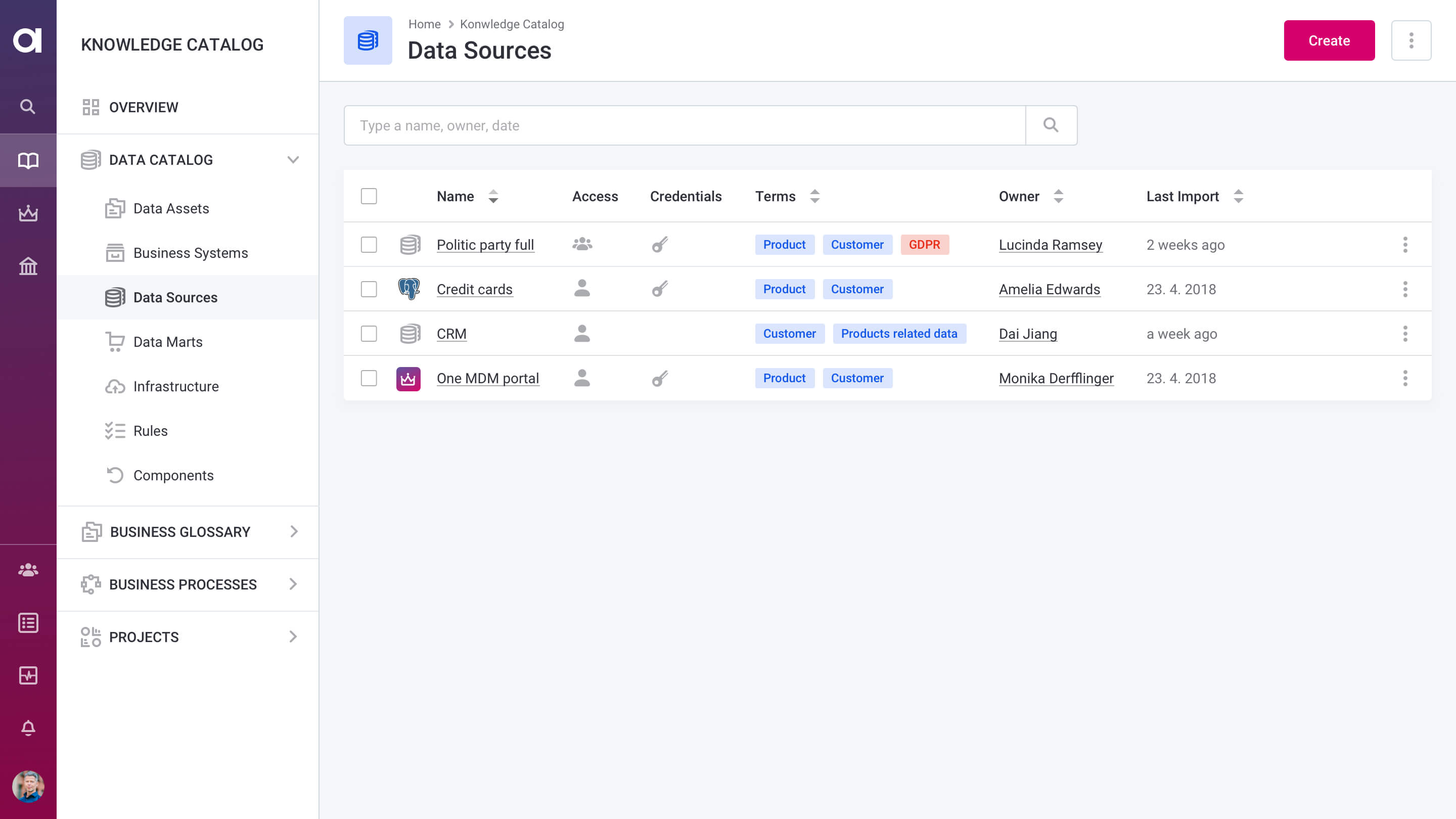
Integrate data from any source
Save development time by deploying reusable configurations and distributing workloads on local, big data, and cloud environments. Then, integrate processing outputs into a data store of your choice.
Data quality is taken care of
Built-in data quality capabilities
Validate data and improve data quality while integrating data. Use hundreds of pre-built transformations and DQ functions, or easily create and reuse your own.
Orchestration
Schedule workflows and configure triggers to launch and queue pipelines.
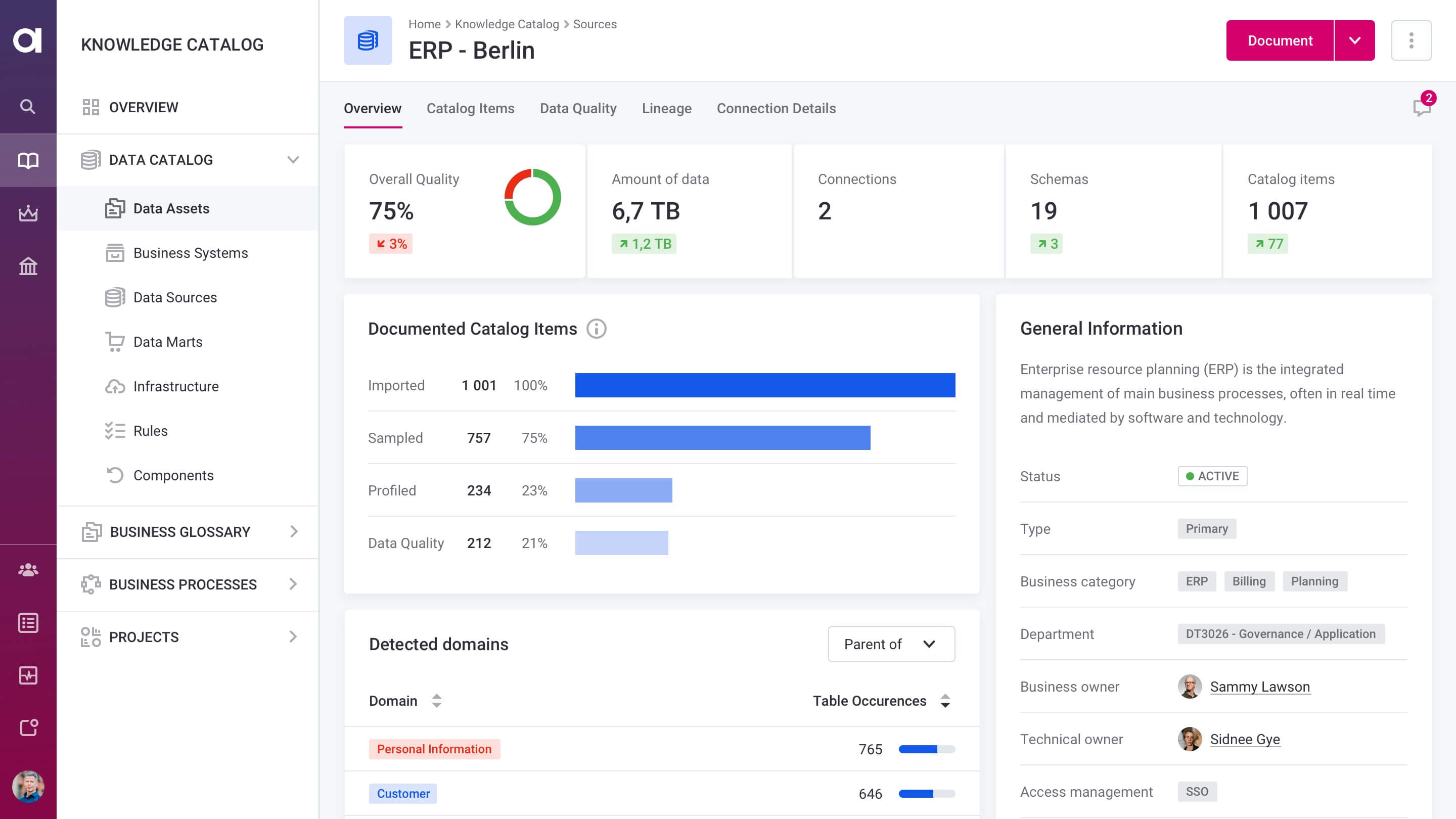
Metadata-driven
Use metadata stored in the Data Catalog to efficiently construct data integration pipelines.
A powerful application for data engineers
Exceptional data integration features
Data transformation
Join, filter, group, aggregate data from multiple sources, write results to files, databases, or any other supported system, including our Data Catalog.
Web services
Publish any pipeline as a web service and use it from your own applications to transform or enrich data.
Data masking
Consistently mask data, create data for test environments, and transfer anonymized data to the cloud. Our smart engine preserves data quality and characteristics.
De-duplication
Identify duplicate records representing the same real-world entity (customers, patients, products, locations, or others) with deterministic and fuzzy matching rules or AI-based algorithms while integrating data.
Data standardization & cleansing
Standardize, cleanse, validate, enrich, and match data as your applications need. Easily move from configuration to testing and deployment. Integrate data quality with existing ETL and CI/CD pipelines.
Data preparation
Easily join and transform data with Ataccama ONE and get your data into shape for your project fast. Thanks to native integration with the data catalog, find or import the right data easily.
External data enrichment & validation
Plug in modules to connect to 3rd party, industry standard data enrichment & validation services.
Call any external API or even scrape web pages.
Orchestration
Manage the execution and scheduling of jobs. Track performance and results from an administration console.
Built for all data people
Ataccama ONE is made for fast analytical teams, highly regulated governance teams, and technical data teams alike.

All data people can do their job better and faster when they can access and trust enterprise data, and see how it’s used.
Reliable, scalable engine
Vertical scaling
Ataccama ONE benefits from increased resources of individual server nodes (CPU cores and RAM for in-memory processing).
Decoupled configuration
Configure data integration pipelines independently of data source and execution environment.
Horizontal scaling
Process any data volumes within a given data processing timeframe with Hadoop, Spark, and Kubernetes clusters.
Integration styles
Batch: structured, semi-structured, text files, XML, and complex formats
Online: SOAP and REST APIs
Messaging (JMS)
Streaming
Distributed processing: Databricks, Amazon EMR, Cloudera, and Hortonworks
Data sources
Relational and NoSQL databases
Files: Avro, Parquet, ORC, TXT, JSON, CSV, Excel
Cloud data sources: Azure, Google Cloud, Amazon S3, and other S3 compatible storages
Adapters for industry-standard message formats
AWS Glue Data Catalog, Hive, HBase
Streaming integration with Apache Kafka
See our Data Integration in action.
Schedule a demo Just pick a timeslot.
Fast and easy.
Data integration resources

Discover the Ataccama
ONE Platform
Ataccama ONE is a full stack data management platform.
See what else you can do.