Gartner's Data & Analytics Summit in Sydney revealed that companies are scrambling to invest in new AI systems and technologies, with an estimated $10 billion going towards AI startups by the end of 2026.
From a survey at the same summit, they found that 45% of these companies were making these investments as a response to the hype around ChatGPT, and 19% are already in pilot mode with a Gen AI project for their company.
One component for all of these projects is clear: You can't have successful AI implementations without adequate data quality. In a survey by Datanami, 33% to 38% of respondents reported failures or delays in AI projects due to poor data quality.
However, a study we conducted on the State of Data Quality revealed that only 7% of the 1000+ respondents said they had "near-total success" with DQ initiatives and "almost never face DQ problems."
So, everyone wants a fancy new Gen AI project – but not many have the data quality necessary to ensure its success. Can you still implement AI initiatives with low DQ? What steps can you take to improve your data quality for upcoming AI projects? Just how important is DQ for AI models?
Before we get into the specifics of how big data quality and AI can help or hurt your initiative, let’s look at the state of AI in general and the flourishing industries versus those running into challenges.
Who benefits from AI right now and why?
Right now, several industries such as online retail, social media, and most business-to-consumer internet companies benefit from AI. The most recognizable are the FAANG companies (Facebook, Amazon, Apple, Netflix, and Google), which utilize AI and leverage the information it provides to adapt their business strategies.
Now let’s look at why these companies have been so successful with their AI initiatives.
Data collected within their own systems
These industries are more equipped to utilize these advantages because their datasets are mainly collected within their own systems, leading to greater control and trust. It's easier for a company like Amazon to use AI to personalize product recommendations than for the CDC building a pandemic simulation AI based on individual (unverified) reports from different states across the U.S. with questionable data quality best practices.
AI connected to their business strategy
You can also connect the success to the benefits they’ve created for these companies. Their revenue model is built around maximizing user attention on their platforms as much as possible. AI helps by making personalized recommendations that tailor these sites’ content to each user, maximizing user attention, and competing with other platforms.
Early adopters of AI systems
These companies have had AI systems in place for over a decade and have quickly become experts in the field. Take Netflix, for example. They employ state-of-the-art data architecture approaches like data mesh to ensure their data quality best practices. Adopting these systems gave them an advantage over companies and industries that were hesitant to instate or are still building similar programs.
Barriers to AI adoption
AI systems won’t come as naturally to other industries. For example, agriculture, healthcare, manufacturing, and logistics may even have similarly sized datasets but face a number of challenges building AI.
Heterogenous datasets
Their datasets aren’t as homogenous as those of consumer internet companies, leading to problems. For example, the healthcare industry’s data can be formatted differently depending on the hospital and region where it was recorded, making it difficult to standardize a learning mechanism for AI.
More complex tasks for AI
Companies might also be struggling to develop successful AI programs because their data or task is more complex. A project like self-driving cars, for example, requires multiple sets of data from numerous sensory sources (multi-dimensionality) working together for a common outcome. Projects like this require problem-solving in real-time with very tight margins for error, making them even more challenging to complete.
Government regulation
Businesses like this can run into barriers when it comes to regulation. One company built a model for a US health insurance company that worked perfectly fine, but in the end, they couldn’t use it because it involved patient records crossing over state lines. Other companies might be hesitant because the impact of a failed AI system runs a much greater risk. If Facebook’s algorithms fail, they may lose one user. If a self-driving car fails, it could kill people.
Spending too much time preparing data
Right now, AI specialists need to create business-specific systems for enterprises in these and other industries. This is much more time-consuming and costly because AI specialists are few and far between, and they need to build each system from scratch, spending most of the time with data quality management to ensure the AI runs appropriately. Back in 2019, Arvind Krishna (IBM Chairman and CEO) said 80% of the work involved with AI projects is data preparation. Today, IBM holds the same perspective, stating that preparing data is "one of the most time-consuming parts" of any data project.
Even an exceptionally advanced company that regularly utilizes machine learning can run into progress-stoppers due to a big data quality issue. Twitter, for example, has had problems with its data collection system.
Information about the same users was stored in separate systems, leading to confusion when building machine learning data quality. “Without a clear idea of what data is available or can be obtained, it is often impossible to understand what ML solutions can realistically achieve,” says the research paper on Twitter struggles.
Data quality is key to successful AI
As you might have noticed, many of the issues above are related to not following data quality best practices and governance. In the end, the question isn’t necessarily about the amount of data you can feed your AI model. A larger set puts you at an advantage by giving you a higher chance of finding high-quality data that is representative of the set as a whole. But having big data quality is much more critical.
"When it comes to training data, quality is more important than quantity. Each bad record can confuse your model and lead it to provide incorrect answers."

It’s also important to understand low-quality data requires more advanced AI models to work with it, so they can parse together disorganized data and make generally incomprehensible sets workable. You can make simple AI models off as little as 10 data points as long as those points are of high quality.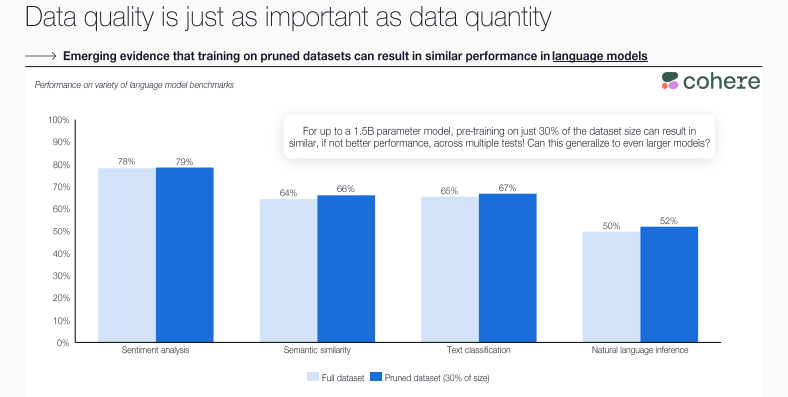 Coatue.com
Coatue.com
This shift is understandable, considering many AI initiatives have failed or are canceled due to poor DQ (87% of data and analytics leaders reported this). Often, the projects will be abandoned by an essential user, stakeholder, or data scientist simply because they don’t trust the data they are working with.
A specific example of this was in 2017 when the Anderson Cancer Center at the University of Texas wanted to use AI to improve their cancer treatments. A data audit revealed they were using old data and several other data quality issues, leading to the project’s failure. Several companies have also reported bad data with inherent biases producing discriminatory results in their AI models that put them at compliance risk.
These issues stem from many factors, not just reformatting bad data or correcting errors, but also data that is poorly labeled or not labeled at all, making it difficult to explain. While companies don’t like to report on failed AI projects, these types of failures and project cancellations happen consistently for similar reasons, even as much as 50% of the time, according to IBM CEO Arvind Krishna.
Understanding the power of data quality without huge datasets
Above, we have shown why data quality is crucial for effective AI engineering. Now, let’s take a look at a different approach to data quality that shows that carefully curated datasets, albeit small, can be sufficient for successful AI implementations.
Andrew Ng, a machine learning data quality expert who worked on famous projects like Google Brain, founded Landing AI, whose purpose is just that. The startup is developing a platform that lets domain experts prepare high-quality datasets for AI training. Its current iteration focused on manufacturing helps domain experts create a library of product defects and upload pictures with examples. This data is then used to train AI and automate the detection of manufacturing flaws with cameras.
This is a great way to ensure data quality for industries with smaller datasets and a lack of pre-trained models.
“When a system isn’t performing well, many teams instinctually try to improve the code. But for many practical applications, it’s more effective instead to focus on improving the data”
Andrew Ng
The data science community seems to agree:
Learn data quality fundamentals
Learn the why, what, how of data quality in a dedicated blog post.
Read blogHow do you ensure data quality for AI?
Now, let’s go to the world of big data again. After all, plenty of industries collects tremendous amounts of data that can be used for AI. Retail, healthcare, pharma, and transportation come to mind.
Thankfully, the tried and true data quality techniques are effective for AI, too.
Data profiling
Although a basic data analysis technique, AI professionals cite data profiling as crucial for understanding data (or performing a sanity check) before using it. Profiling a dataset gives you insight into the following:
- The distribution of values in the columns of interest
- Statistical information: minimum, maximum, median, and average values, and outliers
- Formatting inconsistencies
- And more
All of these are important to understand whether this data set is usable and how you can make it functional if it’s not.
Data preparation
Data scientists and AI researchers always need to tweak the data to work for AI. Whether parsing attributes, transposing columns, or calculating values from data, these users need easy-to-use tools to do that.
Data quality evaluation
You can quickly validate any dataset based on the data domains with a central library of pre-built data quality rules. Provided you have a data catalog with built-in data quality tools. You can easily reuse rules to validate emails, customer names, or internal product codes. You can also have rules to enrich and standardize some data, for example, address data.
Data quality monitoring and evaluation
An even better option for data scientists is having data quality pre-calculated for most datasets they find. They can then further drill down to see what specific problems each attribute has and decide whether they will use it or not.
Automate data quality management for AI
Want to see the above in action? Check out this automated data quality demo.
Watch demoConclusion
As you can see, the world of AI is an ever-evolving space with many competitors. Some of these industries have an advantage, while others are still overcoming barriers.
Every company exists in a different space on the AI-readiness spectrum, but we can still safely conclude that data quality is imperative to any AI project. By preserving the quality of your data, you don’t only increase the chances of success but also negate the need for massive datasets.
If your organization wants to shift towards AI and machine learning data quality, checking your data quality is undoubtedly a place to start.
If you'd like to learn more about data management and AI, join us for a fireside chat where we discuss the biggest talking points in the industry.